路径规划(也叫运动学规划),任务是确定控制输入,以驱动机器人从初始配置和速度到目标配置和速度,同时服从基于物理的动力学模型,且能确保机器人在环境中避开障碍。说白了,就是给你一张地图,且已知障碍物分布,以及起始点和目标点的坐标,希望你根据这些信息,找到一条从起点到终点的能绕开障碍物的有效路径,如果可以,还希望这条有效路径尽可能最优(最短),并且希望找到这条有效路径的时间尽可能短(算法足够高效)
目前流行的路径规划分为两大类:基于采样的路径规划和基于搜索的路径规划。
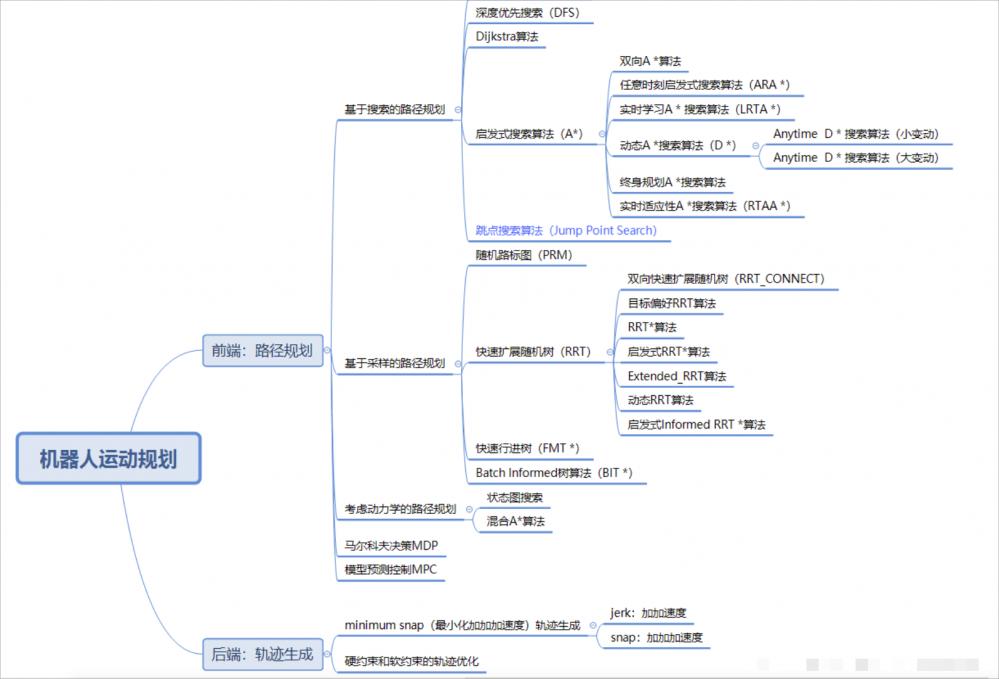
运动规划的状态空间是应用于机器人变换的集合,称为位姿空间(configuration space),引入了 C-空间、C-空间障碍物、自由空间等一系列概念,下面介绍一些概念:
机器人一个位姿指的是一组相互独立的参数集,它能完全确定机器人上所有的点在工作空间 W 中的位置,这些参数用来完整描述机器人在工作空间 W 中的状态。一个位姿通常表示为带有位置和方向参数的一个向量(vector),用 q 表示。
机器人的自由度定义为机器人运动过程中决定其运动状态的所有独立参数的数目,即 q 的维数。
位姿空间是机器人所有可能位姿组成的集合,代表了机器人所有可能的运动结果,称为 C-空间,也可简记为 C。
C-空间中的距离函数定义为该空间中的一个映射
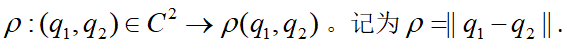
我们有两个节点,一个绿色的起点,一个黄色的终点

对于RRT,我们做的第一件事就是将起点设置为随机树的根,那么我们就拥有了一颗只有根节点的树

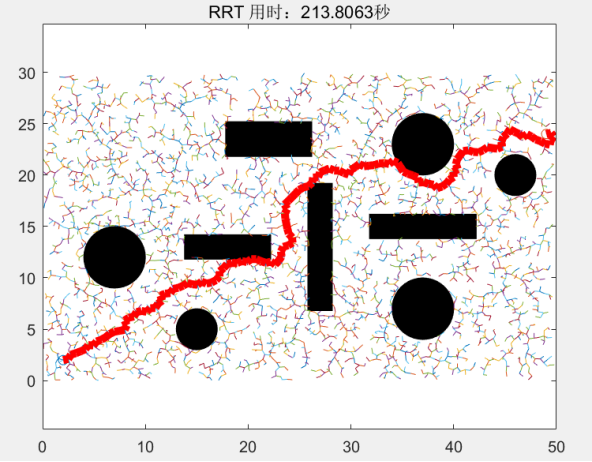
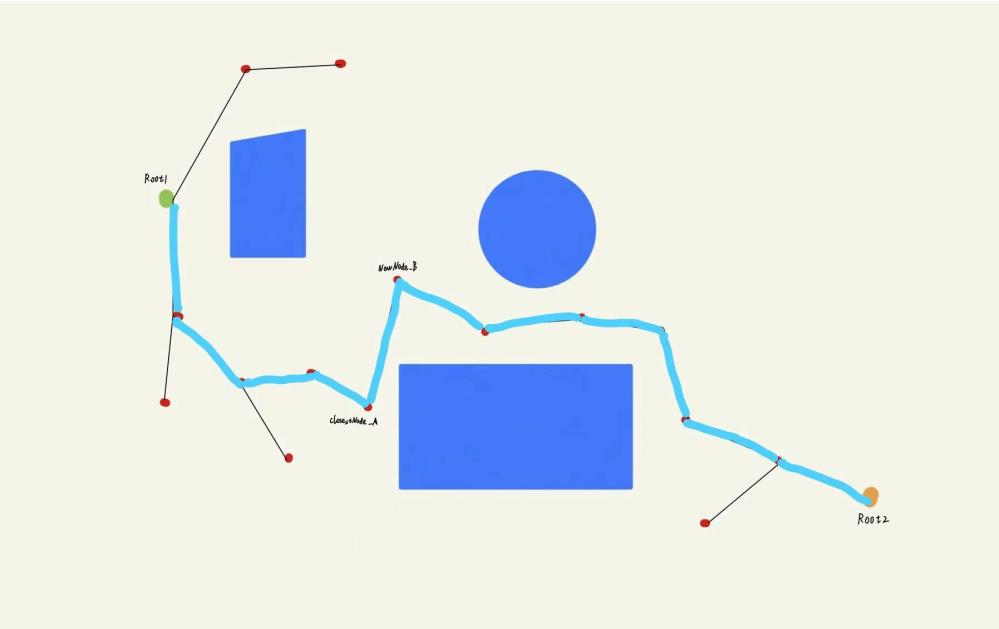
这棵树光秃秃的,只有根节点的话不但难看,而且还没用。那么我们这时候就需要从这个根节点出发,向外拓展出新的叶⼦。拓展的方式很简单,就是随机采样+步⻓限制+碰撞检测。 RRT在每轮迭代中会⽣成⼀个随机采样点NewNode,如果NewNode位于自由区域,那么我们就可以遍历随机树中已有的全部节点,找出距离NewNode最近的节点ClosestNode。利⽤距离函数dist(NewNode, ClosestNode)得到二者之间的距离,如果满足步长限制的话,我们将接着对这两个节点进⾏碰撞检测,如果不满足步长限制的话,我们需要沿着NewNode和ClosestNode的连线⽅向,找出⼀个符合步长限制的中间点,用来替代NewNode。最后如果NewNode和ClosestNode通过了碰撞检测,就意味着二者之间存在边(edge),我们便可以将NewNode添加进随机树中。首先以第一轮迭代为例,因为刚开始我们的随机树中只有根节点,所以⽆论NewNode位于何处,遍历出的最近节点ClosestNode必然是根节点。 假设我们遇到下图这种情况,虽然采样点NewNode位于步⻓限制之内,但是却很不巧没有落在自由区域,即采样点落在障碍物的位置时,这个采样点会被算法舍弃。
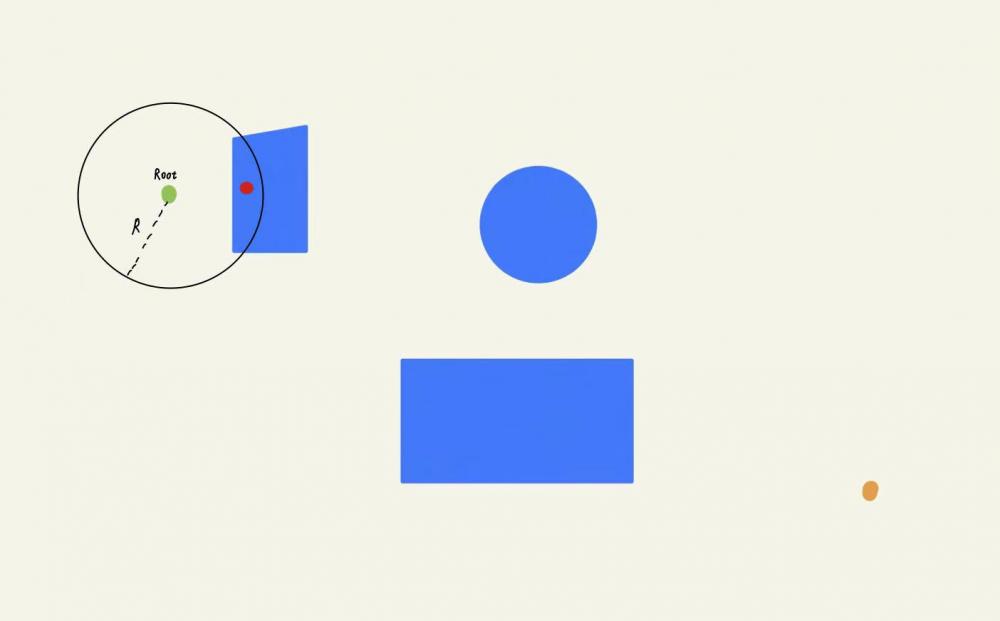
假设我们的步⻓限制为R,也就是说对于每个ClosestNode节点来说,只有当NewNode落在其半径为R的圆的范围内时,这个随机采样点NewNode才有可能被直接采纳。如下图所示,该红⾊随机采样点虽然位于⾃由区域,但是明显在根节点的步⻓限制之外。不过这个节点并不会被简单粗暴地舍弃。⽽是会沿着ClosestNode和NewNode的连线,找出符合步⻓限制的中间点,将这个中间点作为新的采样点。如下图所示,蓝点就可以替代红点作为新的采样点。
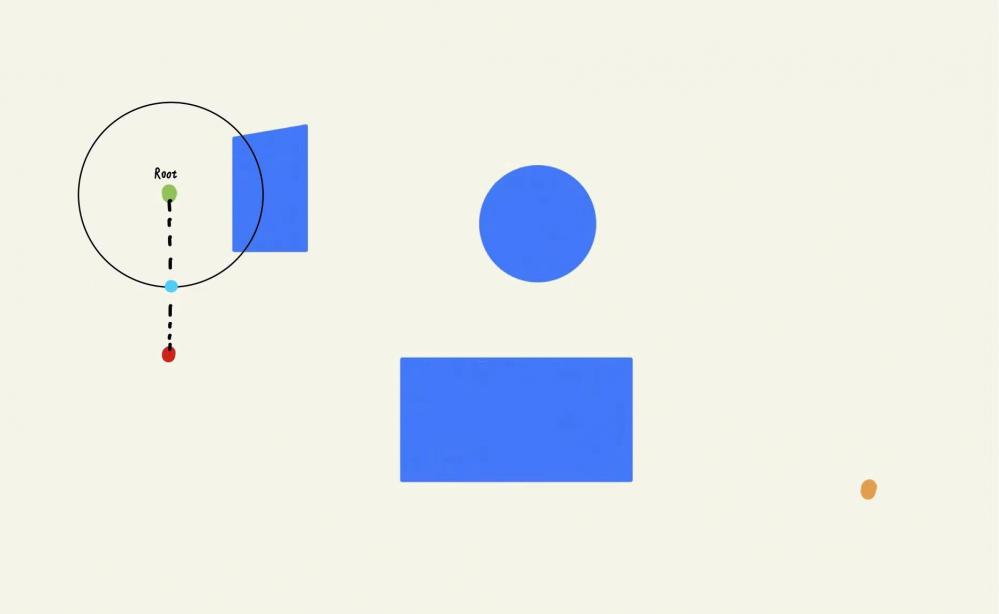
那么假设我们已经通过第⼀轮迭代拓展出第⼀个叶⼦节点A,毫⽆疑问地A的⽗节点就是根节点,假设我们第⼆轮迭代的随机采样点NewNode为图中的点B,B落在A的步⻓限制范围内,但是A,B之间由于障碍物的阻挡,⽆法通过碰撞检测,于是B就会被算法舍弃。
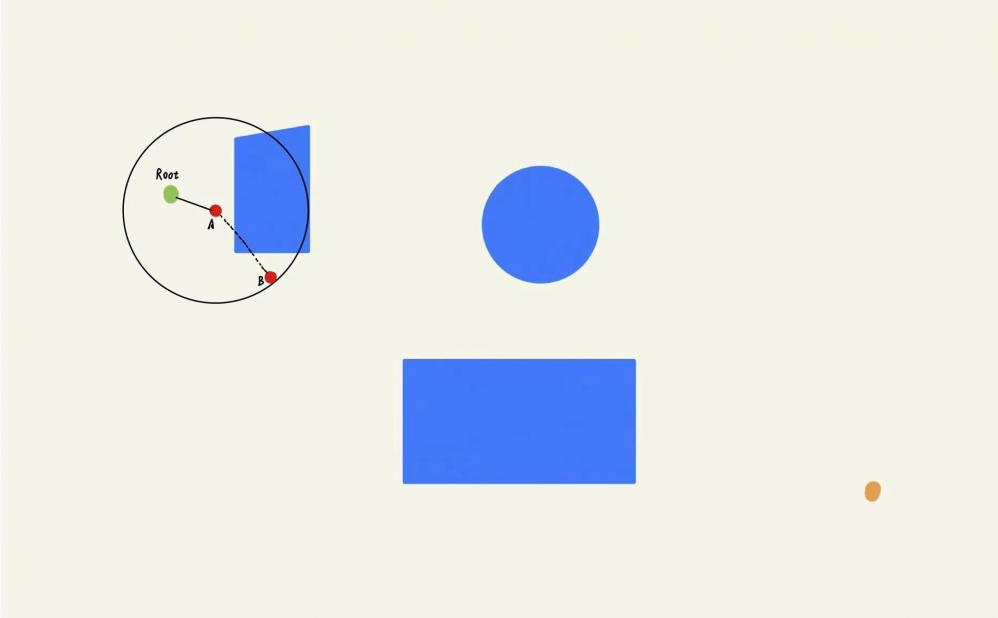
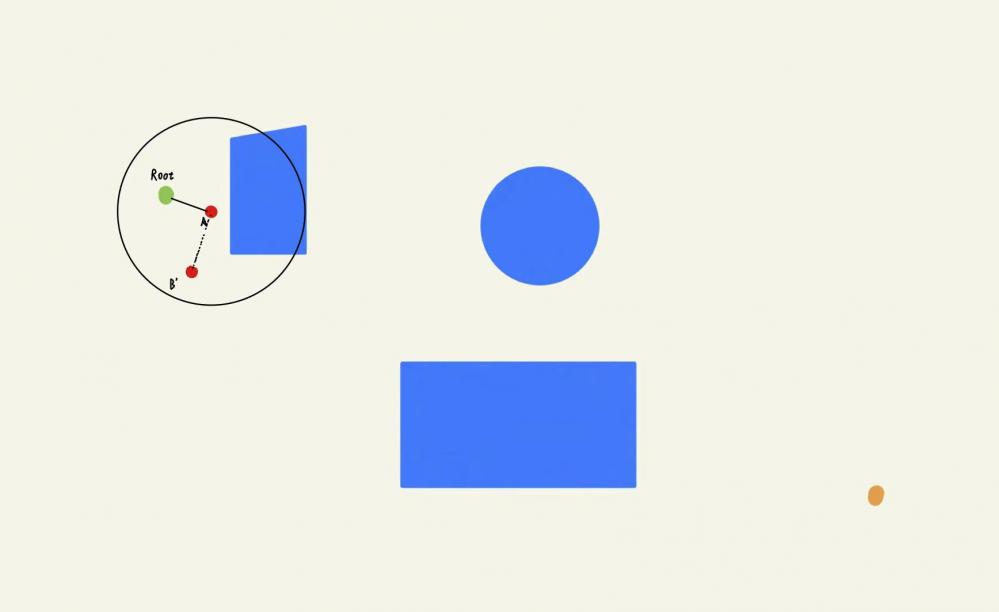
假设我们的随机采样点是下图中的B’,明显B’位于⾃由区域,满⾜步⻓条件,并且可以通过与点A的碰撞检测,那么我们就在B’和A之间添加⼀条边,并且将A设置为B’的⽗节点。学过数据结构的⼩伙伴⼀定知道,在树结构中每个节点最多只有⼀个⽗节点,⽗节点可以拥有多个⼦节点。
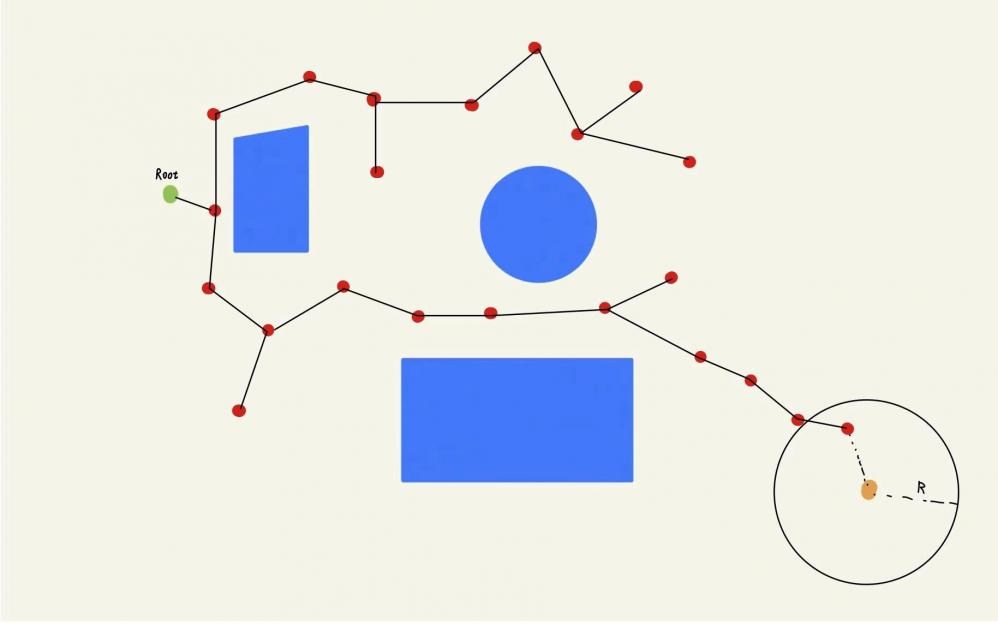
在经历了N轮迭代后,我们已经获得了⼀颗如下图所示的随机树,这时我们发现此时的随机采样点竟然幸运地落在了终点的步⻓限制范围内,并且⼆者之间不存在障碍物。这时我们便可以认为,该采样点和终点之间存在⼀条边,于是将该节点设为终点的⽗节点,并把终点添加进随机树。此时算法就可以结束迭代了,即规划算法收敛。
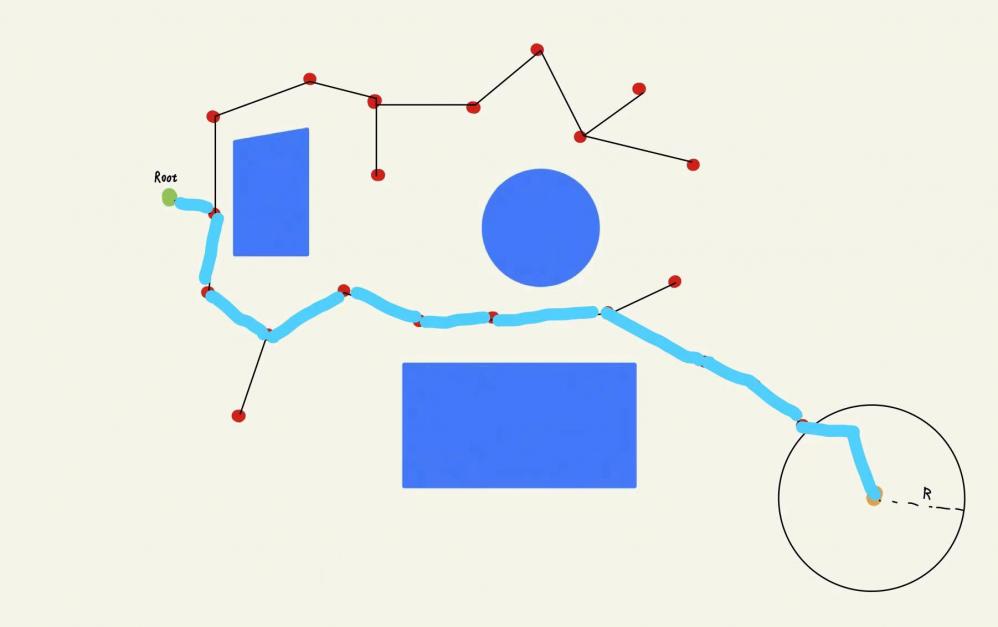
当规划算法收敛以后,只需要从终点开始,沿着其⽗节点进⾏回溯,就可以找 到起点-终点之间的有效路径。
那么总结⼀下,RRT⽣成的每轮迭代中都包含以下这些流程:
1. ⽣成⼀个随机采样点NewNode,并判断采样点是否位于⾃由区域
2. 遍历随机树,找出距离NewNode最近的节点ClosestNode
3. 判断NewNode是否在ClosestNode的步⻓限制范围内,否则寻找中间点替代NewNode
4. 判断NewNode和ClosestNode之间是否存在障碍物,即碰撞检测。
5. 如果NewNode满⾜以上所有约束条件,则将NewNode添加进随机树,设置ClosestNode为NewNode的⽗节点。
6. 判断NewNode是否在终点的步⻓限制范围内,并对其⼆者做碰撞检测。如果满⾜条件则将该NewNode设为终点的⽗节点,并将终点加⼊随机树,即可结束迭代。否则继续迭代。

本节主要介绍了该规划⽅法的理论特性。

如果存在长度为k的连接序列,则将 x_init 连接到 x_goal 所预期的迭代次数不超过k/p
Pf. 参考S.M. Lavalle and J.J. Kuffffner. "Randomized Kinodynamic Planning." The International Journal of Robotics Research. Vol. 20, Number 5, 2001, pp. 378 – 400. 第392页

Pf. 参考S.M. Lavalle and J.J. Kuffffner. "Randomized Kinodynamic Planning." The International Journal of Robotics Research. Vol. 20, Number 5, 2001, pp. 378 – 400. 第393页
当顶点数趋于无穷时,在 x_init 处初始化的RRT包含 x_goal 的概率将趋近于1
Pf. 参考S.M. Lavalle and J.J. Kuffffner. "Randomized Kinodynamic Planning." The International Journal of Robotics Research. Vol. 20, Number 5, 2001, pp. 378 – 400. 第394页
定理1和定理2表示了规划器的收敛率,定理3建⽴了规划器是概率完备的(即,当迭代数趋于⽆穷时,找到解的概率趋于1
我们可以看出,由于算法在未达到收敛条件之前是在不断进⾏迭代的,所以只要在规划的起点和终点之间是存在有效的路径,那么只要迭代的次数够多,那么采样点就够多,随机树就长得越茂密,能探索到的区域就⾜够⼴,就必然可以找到有效的路径。所以RRT是概率完备的。但是由于采样点每次都是随机的,所以算法并不能保证找到的路径是最优的路径。因此RRT是⾮最优的。
1、S.M. Lavalle and J.J. Kuffffner. "Randomized Kinodynamic Planning." The International Journal of Robotics Research. Vol. 20, Number 5, 2001, pp. 378 – 400.
2、Rapidly-Exploring Random Trees: A New Tool for Path Planning
3、https://www.guyuehome.com/9405
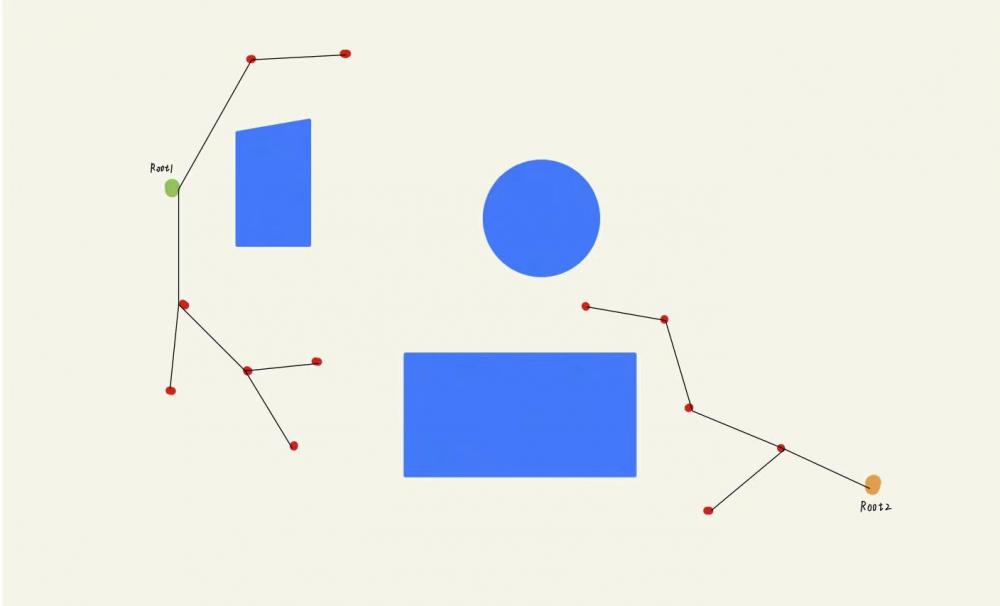
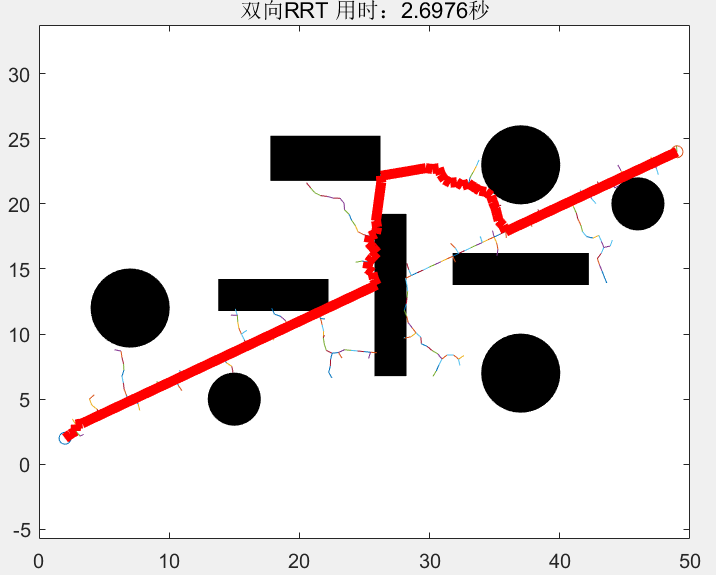
双树RRT是在原本RRT的基础上多加了⼀颗随机探索树,各自从起点和终点向外探索拓展,直到两棵树相遇时规划算法收敛。这种改进过的探索策略可以⼤⼤提⾼RRT的运⾏效率。 双树RRT中存在两颗随机树,我们将其命名为A和B,A以起点为根节点,B以终点为根节点。两颗随机树的拓展方式和单树RRT的别无二致,同样都需要经历随机采样+步⻓限制+碰撞检测这三个步骤,但是不同的地⽅在于双树RRT的随机树是交替生长的,⽐⽅说第⼀轮迭代中A树向外⽣⻓,第⼆轮便切换为B树⽣⻓,如此循环。 在每轮迭代中,随机树除了向外拓展之外,还会多出⼀个步骤,就是遍历另一颗随机树中的所有节点,找出离NewNode最近的节点,用于判断两颗随机树是否相遇。 假设算法经历了N次迭代以后,已经拓展出如下图所示的两颗随机树。并且在下⼀轮迭代中,轮到A树进⾏拓展,A树在图中⽤绿⾊线条表示,B树⽤黄色线条表示。
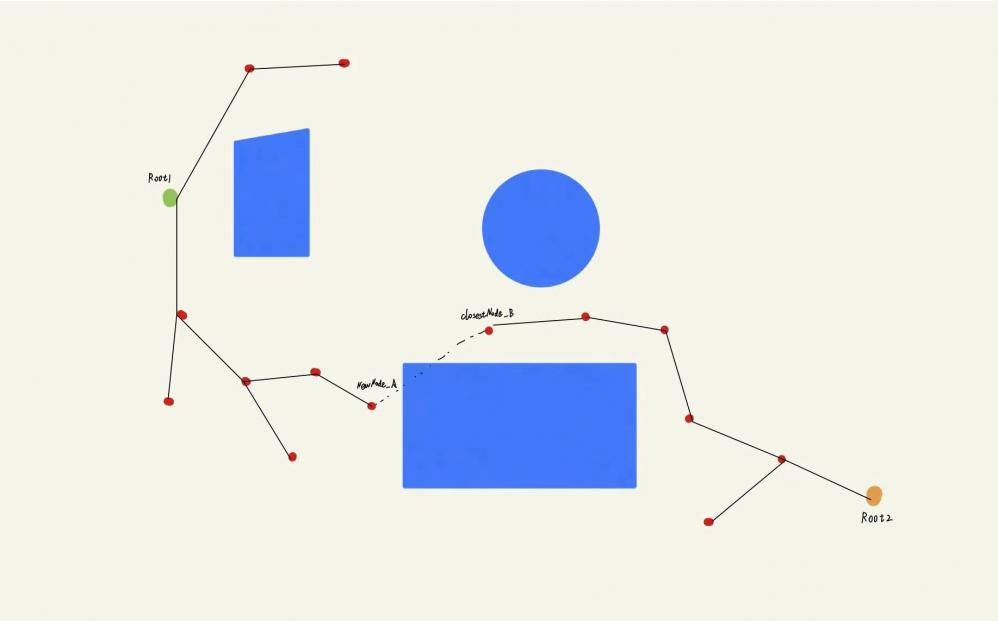
当进⼊本轮迭代后,算法成功拓展出A树的新节点NewNode_A,此时算法将遍历B树中的所有节点,找出B树中离NewNode_A最近的节点ClosestNode_B。并判断⼆者是否满⾜步⻓限制以及是否可以通过步⻓检测。如下图所示,这种情况明显⽆法通过碰撞检测。那么A树和B树在这⼀轮迭代中⽆法相遇,需要接着下⼀轮迭代。
进⼊下⼀轮迭代,这次便切换为B树进⾏拓展,假设算法拓展出的NewNode_B以及遍历A树后得到的ClosestNode_A如下图所示,经过判断发现⼆者满⾜步⻓限制并且通过了碰撞检测,那么这时A树和B树就成功得相遇了,规划算法收敛
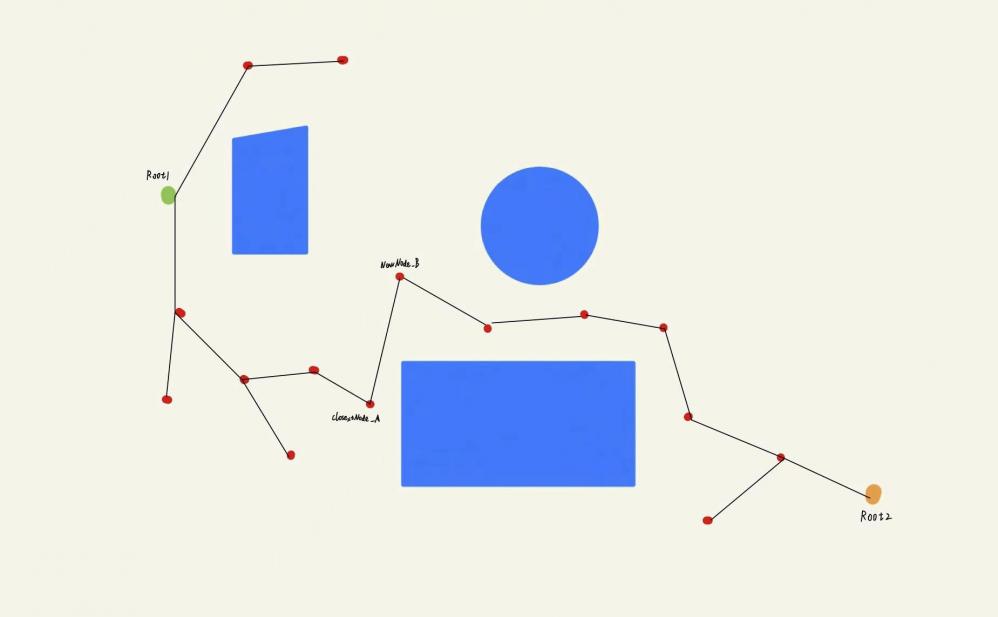
当算法收敛以后,只需在两棵树的相遇处分别沿着⽗节点回溯便可以找出从起点到终点的有效路径。
注意:
双向RRT和RRT的区别不仅仅是在于双向生长,双向RRT比RRT更“贪心”,相比于RRT在生长RRT树的时候,是每产生一个随机点,如果能通过碰撞检测,就往该随机点的方向生长一次,然后该随机点就被废弃了,下一步想继续生长RRT树的话,就只能继续生成新的随机点,每个随机点最多利用一次。而双向RRT在生长RRT树时,先先生成一个随机点,然后,该树往该随机点的方向生长,直到碰到障碍物或则生长到该随机点,这样,一个随机点就被多次利用,加快了速度。
双向RRT的收敛性分析可以应用RRT的收敛性分析
1、RRT-Connect: An Efficient Approach to Single-Query Path Planning
2、https://www.guyuehome.com/9405
相比于最原始的 RRT 算法的一些缺点,提出的一种改进的 RRT 算法
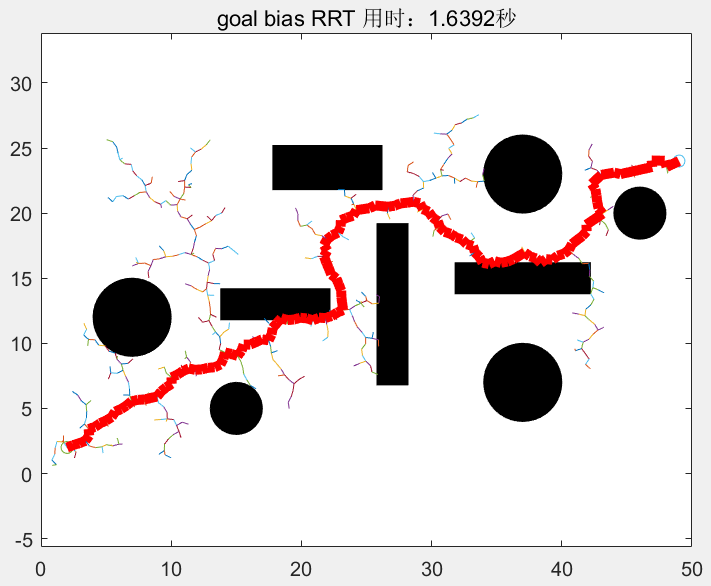
为了加快随机树到达目标点的速度,简单的改进方法是:在随机树每次的生长过程中,根据随机概率(0.0 到 1.0 的随机值 p)来选择生长方向是目标点还是随机点。2001 年,LaValle在采样策略方面引入 RRT GoalBias 与 RRT GoalZoom,RRT GoalBias 方法中,规划器随机采样的同时,以一定概率向最终目标运动;RRTGoalZoom 方法中,规划器分别在整个空间和目标点周围的空间进行采样。
和普通RRT的区别仅在于随机撒点的时候有区别,这个p越大,算法越快,但对于复杂地形,可能会陷入局部极小处,反而变慢。一般取p=0.1
Rapidly-Exploring Random Trees: A New Tool for Path Planning
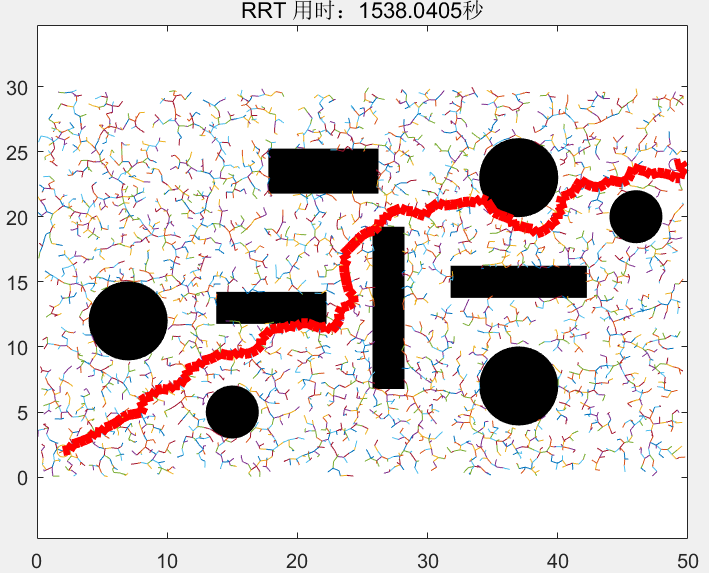
在现实世界的场景中,通常会出现这样的情况:有关环境的初始可用信息是不完整的,或者环境本身是动态的。在这些情况下,当接收到新信息时,初始解决方案可能会失效,例如通过机载传感器。当这种情况发生时,通常会放弃当前的 RRT,并从零开始生长新的 RRT。这可能是一项非常耗时的操作,尤其是在规划问题很复杂的情况下。另一方面,在确定性规划界存在重规划算法,当这种变化发生时,它们能够有效地修复之前的解决方案,而不需要从头重新规划。这就是通过连续域规划路径的问题,如果每次更新地图,都用RRT重新规划,效率相当低下。Extended_RRT则专门用于解决这种动态路径规划问题。
Extended_RRT的思路是这样的:在老地图中,由RRT算法得出的路径,在障碍物动态变化不太大的前提下,在新地图中,大概率也是能通过的,就算障碍物变化很大,之前的路径也或多或少包含了当前障碍物区域的信息,所以,在新障碍物区域中,在重新规划路径时,原有的初始RRT路径的信息可以利用上,而没有必要完完全全重零开始用RRT来规划。
那么如何利用上初始RRT路径的信息呢?
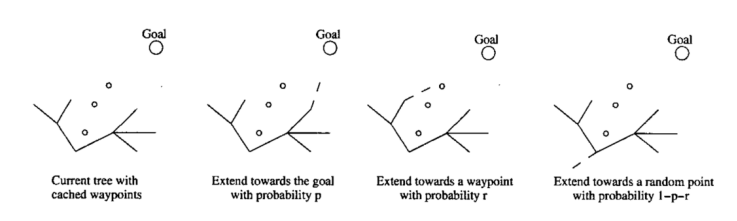
思路如下:
在老地图上先用RRT算法的处一条初始路径,将这条初始路径上的节点存储在集合waypoints中,当环境更新后,希望在新地图上得出一条路径,在随机撒点的步骤,新的随机点有概率p落在目标节点处,此外,还有r的概率落在waypoints的节点中,剩余1-p-r的概率在目标区域内随即撒点。这样在重规划时,就可以把初始路径的信息利用进来。完成随机点选取后,剩余的碰撞检测、树的生长、路径回溯步骤与RRT一致。
总结:
Extended_RRT适用于需要反复路径重规划的场景中,效率比直接重新进行RRT要高得多,和RRT的主要区别在于,在选取新的随机点时,利用上了初始路径的信息,而不是完全随机撒点。

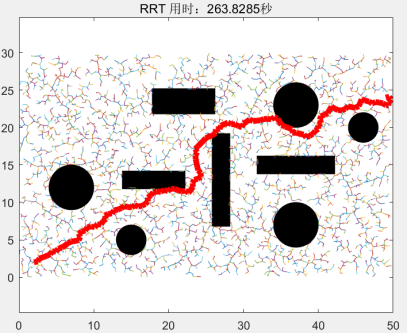
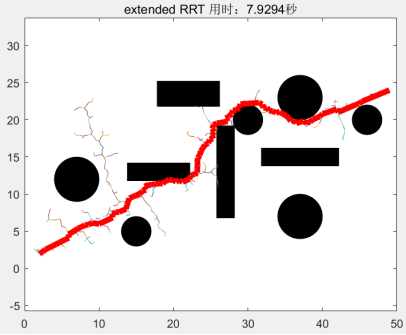
1、Real-Time Randomized Path Planning for Robot Navigation*
2、Extended RRT algorithm with dynamic N-dimensional cuboid domains
3、Replanning with RRTs
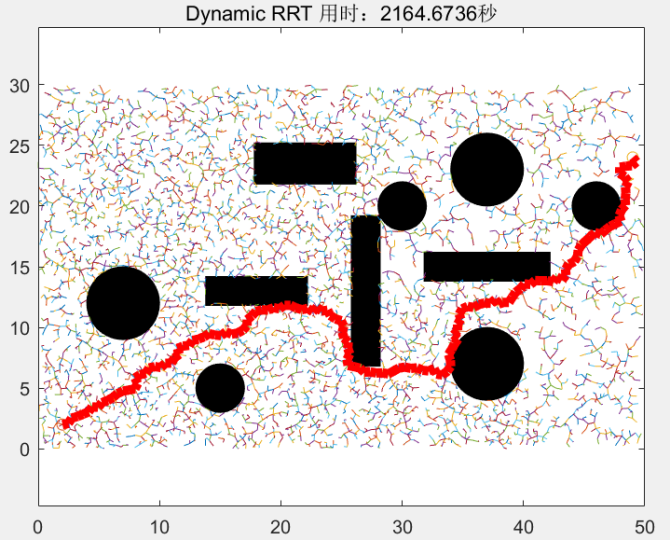
Dynamic RRT和Extended RRT一样,也是用来解决动态路径规划问题,它们的思想有一点是共通的,那就是不要完全放弃初始RRT生成的树或初始路径的信息,而是在此基础上重新规划。Dynamic RRT和Extended RRT的区别在于,Extended RRT利用的是RRT生成的初始路径的信息,而Dynamic RRT利用的是RRT生成的初始RRT树的信息。
思路如下:
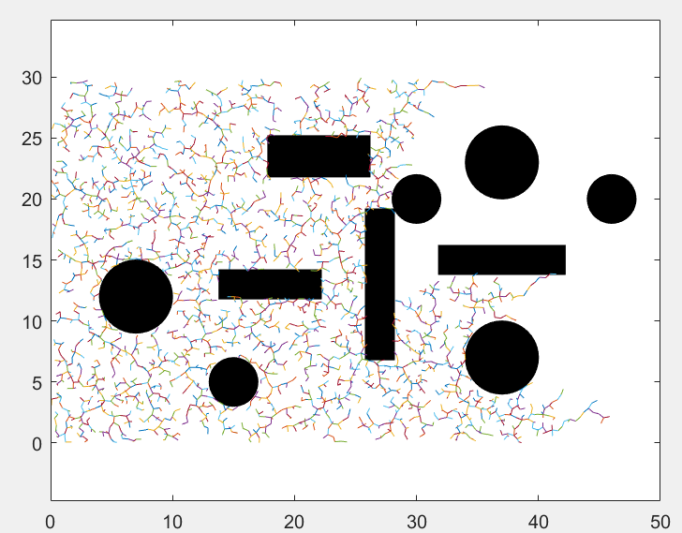
在老地图中,用RRT算法生成了一个RRT树,在新地图中,原始RRT树的节点信息(坐标、父节点)存储在一个节点集合中。在新地图中,先检测新地图中比老地图多出的障碍物,然后,以碰撞检测为评判根据,删除老节点集合中与新障碍物无法通过碰撞检测的节点和边。的到一颗修建过后的与新地形无碰撞的修剪后RRT树,然后再在这颗修剪后的额RRT树的基础上,继续生长这棵树,直到这棵树连接起点和终点,然后回溯路径,得出新路径。
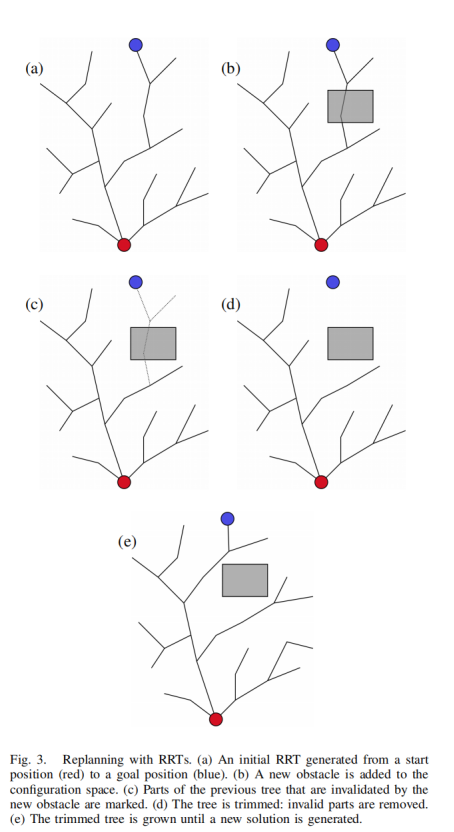
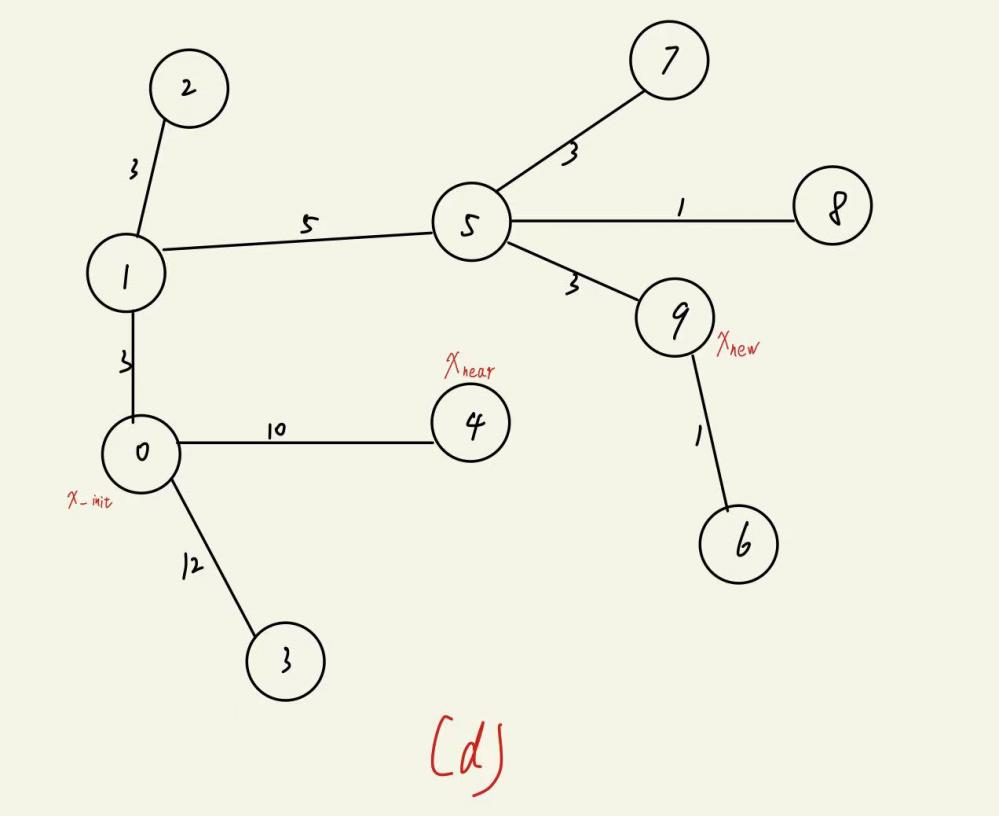
①从从初始配置到目标配置生成的 RRT 开始(图(a))。
②当配置空间发生变化时(例如通过接收新信息),将RRT中因这些变化而失效的所有部分标记为无效(图(b)和(c))。
③然后我们修剪树以去除所有这些无效部分(图(d))。
④此时,保证树中剩余的所有节点和边都是有效的,但树可能不再达到目标。最后,我们把树长出来,直到再次达到目标

加入新的障碍物后,被该障碍物折断的剩余的图:
在原来的树的基础上,继续生长后的图:
Replanning with RRTs
RRT*是一种基于采样的最优化路径规划方式,与RRT的区别是,RRT尽量使新节点以及其周围的节点到起点的cost(可以是路径或者时间等目标函数)最短,而不是仅仅寻找离它近的节点,而且在找到路径后不会停止,而是继续进行采样来优化得到的路径。
尽管RRT算法是一个相对高效率,同时可以较好的处理带有非完整约束的路径规划问题的算法,并且在很多方面有很大的优势,但是RRT算法并不能保证所得出的可行路径是相对优化的。因此许多关于RRT算法的改进也致力于解决路径优化的问题,RRT*算法就是其中一个。RRT*算法的主要特征是能快速的找出初始路径,之后随着采样点的增加,不断地进行优化直到找到目标点或者达到设定的最大循环次数。RRT*算法是渐进优化的,也就是随着迭代次数的增加,得出的路径是越来越优化的,而且永远不可能在有限的时间中得出最优的路径。因此换句话说,要想得出相对满意的优化路径,是需要一定的运算时间的。所以RRT*算法的收敛时间是一个比较突出的研究问题。但不可否认的是,RRT*算法计算出的路径的代价相比RRT来说减小了不少。RRT*算法与RRT算法的区别主要在于两个针对新节点 xnew 的重计算过程,分别为:
·重新为 xnew 选择父节点的过程
·重布线随机树的过程
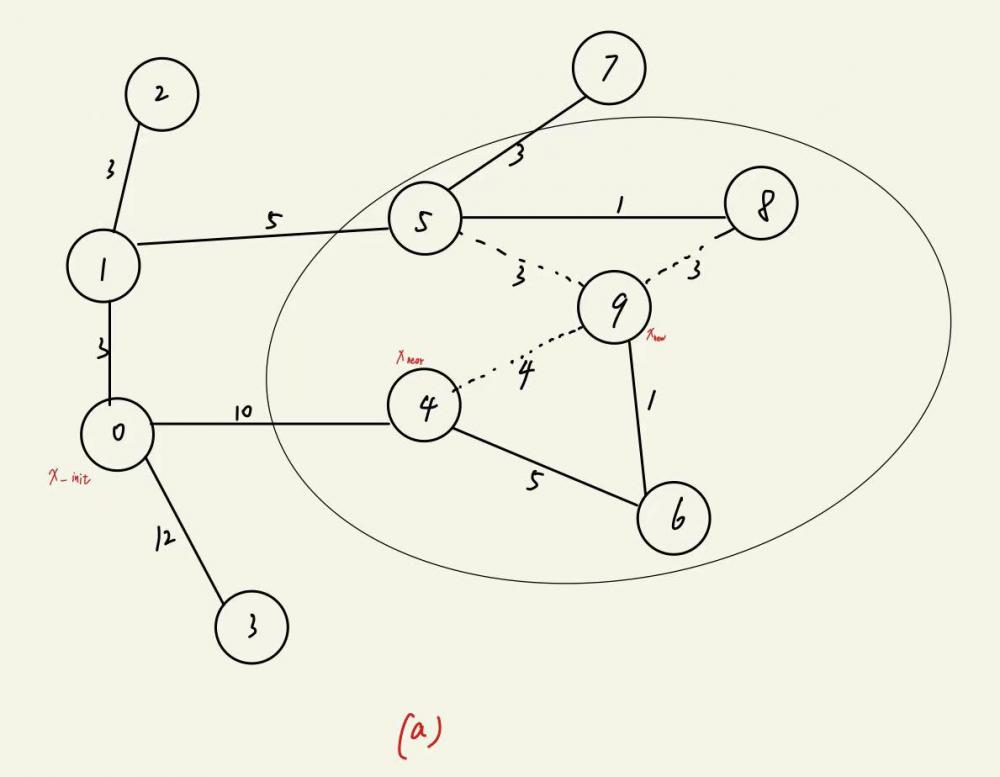
在新产生的节点 xnew 附近以定义的半径范围内寻找“近邻”,作为替换 xnew 父节点的备选。依次计算“近邻”节点到起点的路径代价加上 xnew 到每个“近邻”的路径代价,具体过程见上图。
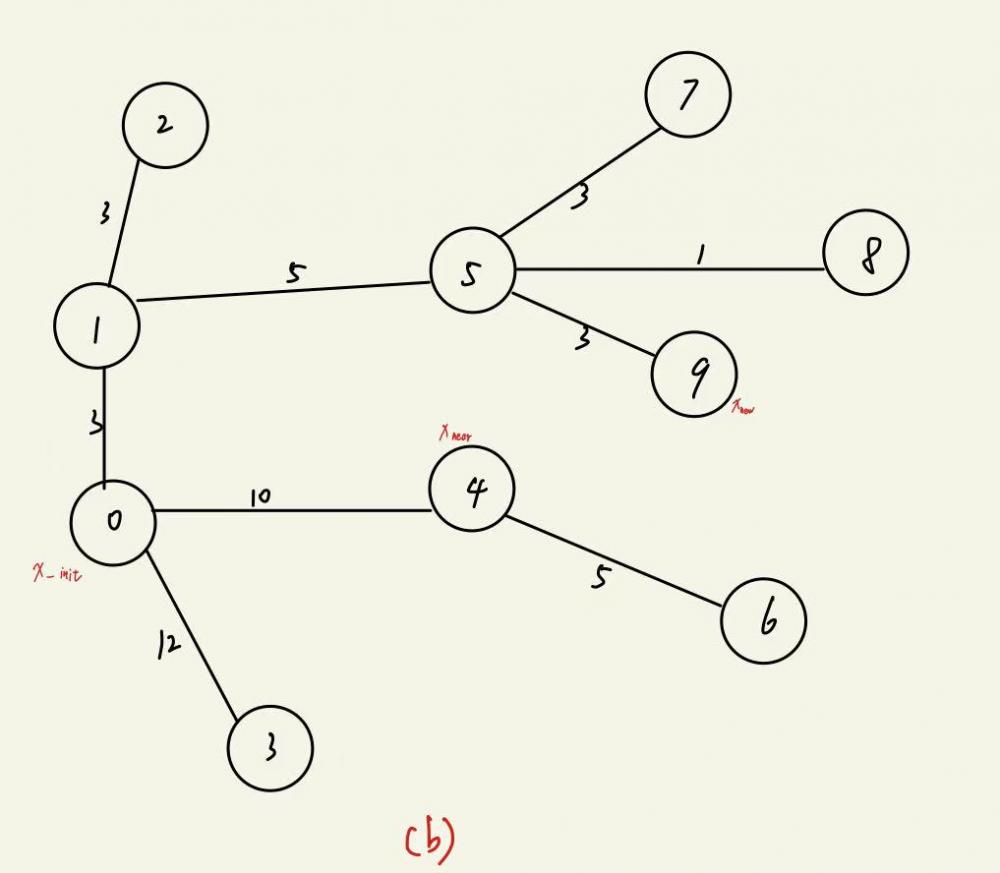
图(a)中表现的是随机树扩展过程中的一个时刻,节点标号表示产生该节点的顺序,0节点是初始节点,9节点是新产生的节点 xnew,6节点是产生9节点的 xnear,节点与节点之间连接的边上数字代表两个节点之间的欧氏距离(这里我们用欧氏距离来表示路径代价)。
在重新找父节点的过程中,以9节点 xnew 为圆心,以事先规定好的半径,找到在这个圆的范围内 xnew 的近邻,也就是4,5,8节点。
原来的路径0 - 4 - 6 - 9代价为10 + 5 + 1 = 16,备选的三个节点与 xnew 组成的路径0 - 1 - 5 - 9,0 - 4 - 9和0 - 1 - 5 - 8 - 9代价分别为3 + 5 + 3 = 11,10 + 4 = 14和3 + 5 + 1 + 3 = 12,因此如果5节点作为9节点的新父节点,则路径代价相对是最小的,因此我们把9节点的父节点由原来的节点4变为节点5,则重新生成的随机树如图(b)所示。
在为xnew 重新选择父节点之后,为进一步使得随机树节点间连接的代价尽量小,为随机树进行重新布线。过程示意如上图重布线的过程也可以被表述成:如果近邻节点的父节点改为 xnew 可以减小路径代价,则进行更改。
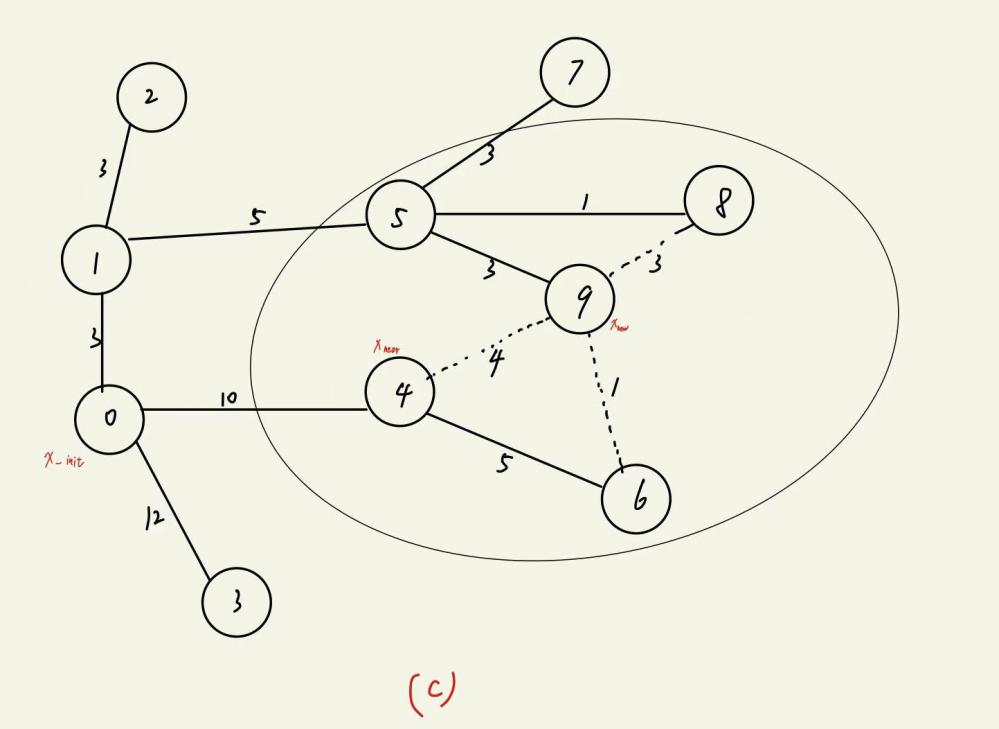
如图(c),9节点为新生成的节点 xnew ,近邻节点分别为节点4 , 6 , 8 。它们父节点分别为节点0 , 4 , 5。路径分别为0 - 4,0 - 4 - 6,0 - 1 - 5 - 8,代价分别为10,10 + 5 = 15 和3 + 5 + 1 = 9。
如果将4节点的父节点改为9节点 xnew ,则到达节点4的路径变为0 - 1 - 5 - 9 - 4,代价为3 + 5 + 3 + 4 = 15 大于原来的路径代价10,因此不改变4节点的父节点。
同理,改变了8节点的父节点,路径代价将由原来的9变为14,也不改变8节点的父节点。如果改变6节点的父节点为 xnew 则路径变为0 - 1 - 5 - 9 - 6,代价为3 + 5 + 3 + 1 = 12小于原来的路径代价15,因此将6的父节点改为节点9,生成的新随机树如图(d)。
重布线过程的意义在于每当生成了新的节点后,是否可以通过重新布线,使得某些节点的路径代价减少。如果以整体的眼光看,并不是每一个重新布线的节点都会出现在最终生成的路径中,但在生成随机树的过程中,每一次的重布线都尽可能的为最终路径代价减小创造机会。
RRT*算法的核心在于上述的两个过程:重新选择父节点和重布线。这两个过程相辅相成,重新选择父节点使新生成的节点路径代价尽可能小,重布线使得生成新节点后的随机树减少冗余通路,减小路径代价。

1、Sampling-based Algorithms for Optimal Motion Planning
2、https://blog.csdn.net/weixin_43795921/article/details/88557317#t0
3、https://zhuanlan.zhihu.com/p/51087819
最初,RRT*-Smart 像 RRT* 一样随机搜索状态空间。类似地,找到第一条路径就像 RRT* 会尝试通过配置空间中的随机采样来找到路径一样。一旦找到第一条路径,它就会通过互连直接可见的节点来优化它。此优化路径产生用于智能采样的偏置点。在这些偏置点,采样以规则的间隔进行
随着算法的进展和路径的不断优化,此过程将继续进行。每当找到更短的路径时,偏差就会转向新路径。
RRT*是一边生长一边优化的,RRT*的重心在于找到最优路径。RRT*树生长到能连接起点和终点后,这就已经有一条初始路径了。
这颗RRT*树可以继续生长,越生长可以得到的路径相比初始路径会越优。然而,这个继续生长的过程对于RRT*而言效率非常低,由此衍生出RRT*-smart算法,专门解决这一问题。
注意到,RRT*-smart是在RRT*算法已生成初始路径后,在此基础上,想对初始路径继续优化的步骤才起作用,所以RRT*-smart对于生成初始路径并没有加速帮助。
RRT*-smart的优势在于:它专注于提升路径接近障碍物拐点处的优化速度。RRT*-smart算法的思路是这样的:
在原始RRT*算法的基础上加了两步:
路径优化的本质是利用三角形两边之和大于第三边
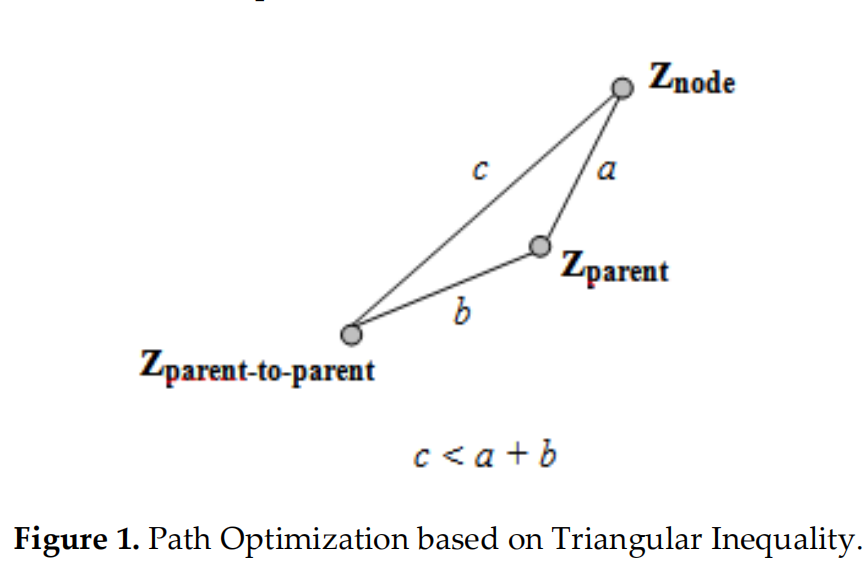
假设RRT*生成的初始路径长这样
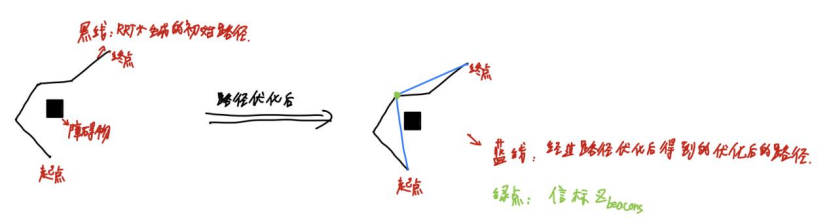
具体操作如下:
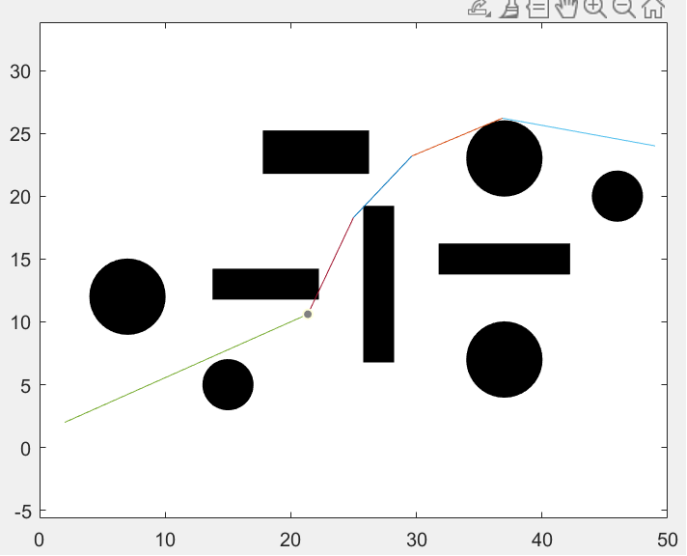
一旦RRT*给出了一条初始路径,将初始路径中彼此可见的节点直接相连。迭代过程从xgoal开始,向xinit检查与每个节点的连续父节点的直接连接,直到无冲突条件失败。下图给出一个示例。
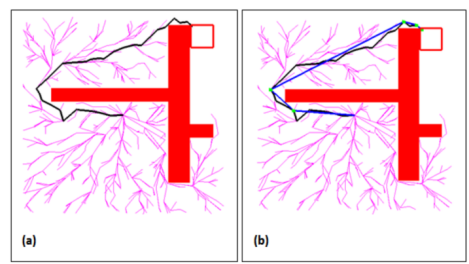
信标(Z_beacons):经过路径优化后的路径中除了起点和终点之外的节点,标记为信标(Z_beacons),如上图中的绿点。
在RRT*算法中,在生成初始路径后,在此RRT*树的基础上继续采点,采点越多,路径优化效果越好,但此采点,是完全随机的采点,因此效率低下,RRT*-smart则不是完全随机的采点。
在RRT*-smart算法中,利用了这样一种思想:智能采样背后的想法是通过生成尽可能靠近障碍物顶点的节点来接近最优性。
在基于采样的RRT*-smart中,路径仅沿着靠近障碍物拐点的外围进行优化,解决的办法就是:在障碍物拐点的外围多多采点。如下图所示:
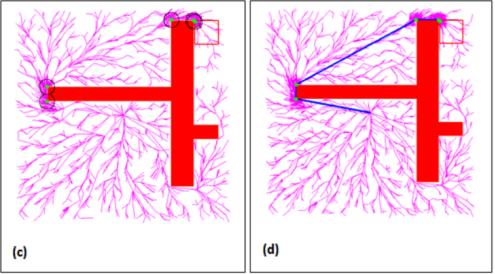
问:那么RRT*-smart如何实现在障碍物拐点的外围多多采点呢?
答:利用①路径优化过程中给出的信标(Z_beacons)。
一旦找到初始路径,智能采样就会开始,在以Z beacons为中心的半径为R beacons的球中直接生成一定数量的样本。采样偏向于这些信标,因为它们提供了有关障碍物顶点(或圆形障碍物的外围)位置的有用线索。因此,这些信标需要被最大节点包围,以优化这些转弯处的路径。与 RRT* 相比,这一特征迫使所提出的算法以更少的迭代次数达到最优解。
注意:
信标(Z_beacons)是需要随着优化路径的更新而更新的。即当z_goal.cost变小时,说明路径得到了优化,那么就要启用之前①路径优化算法来重新确定新的z_beacons。


下图中的线段代表由RRT*生成的初始RRT树,圆圈代表在初始RRT树基础上,继续采点的分布,可见在几个“拐点处”的圆形领域内我们有额外的采点以加强在这部分的采点
路径优化后确定出拐点
经过路径优化后的路径:
1、RRT*-SMART: A Rapid Convergence Implementation of RRT*
2、Rapid convergence implementation of RRT* towards optimal solution
FMT*算法专门针对解决高维构型空间中的复杂运动规划问题,它是为高密度障碍物的环境构建的算法。该算法被证明是渐近最优的,并且比同类型算法(RRT*)更快收敛到最优解。FMT*算法在预先确定的概率绘制的样本数量上执行“惰性”动态规划递归,以生长路径树,该路径树在成本到达空间中稳定地向外移动。
FMT*的最终产物是一棵树,它在连续空间中获取一批样本,然后它能在图中使用惰性的动态编程搜索该样本集合,并以此找到路径,这也是一个渐进最优的解决方案,FMT*相比于RRT*的加速效果优势在高维和碰撞检查很昂贵的情况下尤其突出。很棒的一点是,FMT*是从起始位置开始构建,而不是像RRT*是在空间的任意位置采点,因为这可能会得到非常远的点或非常近的点,这有什么好处呢?这意味着你不必在树中回溯以进行重布线,因为这在计算上效率低下。FMT*比RRT*更好,因为它创建的连接接近最佳,没有重布线。
FMT*算法在预先确定的采样点数量上执行前向动态规划递归,并相应地通过在代价到达空间中稳步向外移动生成路径树。FMT*执行动态规划递归,其特点有三个关键特征:
·它是为磁盘连接图量身定制的,其中两个样本的距离低于给定的界限(称为连接半径)则这两个样本被认为是邻居,因此是可连接的。
·它同时执行图构造和图搜索。
·为了评估动态规划递归中的即时成本,算法“懒惰地”忽略了障碍物的存在,每当与新样本的局部最优(假设没有障碍物)连接与障碍物相交时,该样本就会简单地跳过并留待以后,而不是在邻域中寻找其他连接。
注意:
FMT*的样本点是提前生成好的,然后把这些点固定,再利用这些固定好的点来生成行进树,注意区别于RRT*那一套,RRT*是生成随机点的同时,生成行进树。

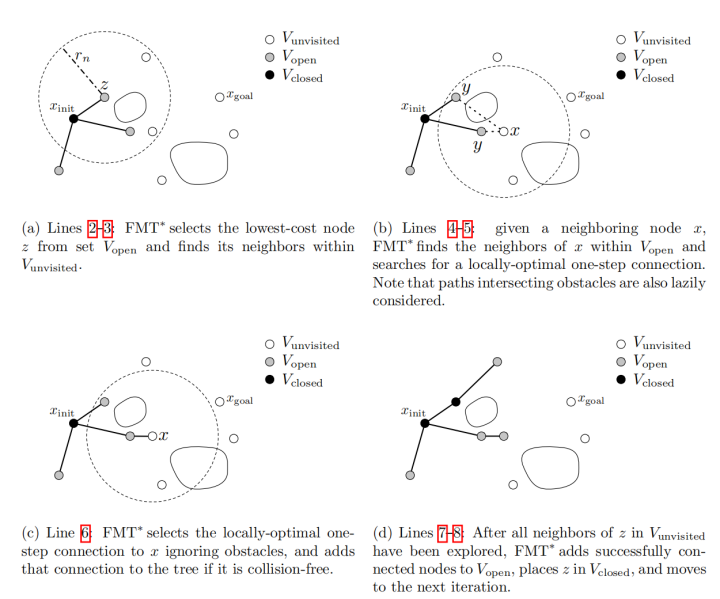



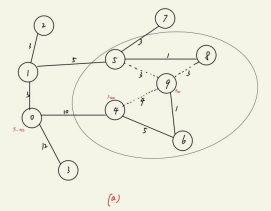
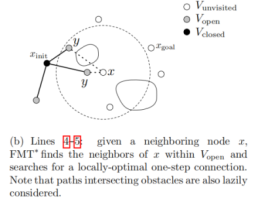
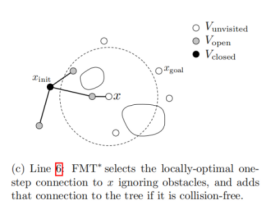
上图(a)是RRT*添加新节点的某一步,上图(b)(c)是FMT*添加新节点的某一步。
先看RRT*,节点9是新考虑的节点,它在第一次重布线时,需要从它的所有邻居节点中找出一个父节点,使得节点9到达起始节点的cost最小,因此节点9需要计算它到4、5、6、8号节点的距离并同时进行碰撞检测,因此,第一次重布线过程就要求待加入的节点对它的所有邻居节点进行一次碰撞检测,第二次重布线过程也需要计算距离和碰撞检测,但这在第一次重布线过程中做过了,可以记录先来直接利用,因此第二次重布线过程碰撞检测这一步可以不用重复进行,因此,总的来说,RRT*每新加入一个节点,该节点需要对它的所有邻居节点进行一次碰撞检测。
再看FMT*,上图(b)(c)中的x就是新考虑的节点,在图(b)中,x需计算它到集合V_open中所有的邻居节点的cost,但不需要进行碰撞检测,从中选择一个能使它到达初始节点总cost最小的节点作为它的父节点,然后,对它和这个父节点的连线进行碰撞检测,如果能通过碰撞检测,则加入x,若不能,则下一个x,因此,总的来说,FMT*每新加入一个节点,永远只需要进行一次碰撞检测。
FMT*比RRT*每新加入一个节点需要进行的碰撞检测次数少得多,而且FMT*也是渐进最优的,这就是FMT*相比于RRT*的优势所在。

下图中的 圆圈代表提前采好的随机点
Fast Marching Tree: a Fast Marching Sampling-Based Method for Optimal Motion Planning in Many Dimensions∗
在RRT中,当初始路径已经生成之后,如果重点在初始路径周围进行采样的话,可以明显提高路径优化效率。Informed RRT就是进一步优化了采样函数,采样的方式是以起点和终点为焦点构建椭圆形采样区域。
回顾一下RRT*-smart,因为在某区域撒点越多,该区域的优化效果越好,而单纯的RRT*是在全域内随机撒点,优化效果没有得以集中,RRT*-smart认为经过路径优化后的路径的拐点在障碍物的附近,它认为这个拐点的附近需要着重优化,所以RRT*-smart在进一步撒点的过程中,将一些随机点偏袒的撒在这个拐点的附近邻域。
这里的informed RRT*也是这样认为,它认为单纯的RRT*在整个区域内随机撒点,优化效果太过分散,如果我能知道我最终优化的路径在哪一块区域,那我就只在这一区域内撒点不就好了吗?informed RRT*就是这样做的。
注意:
informed RRT*是在RRT*算法给出一条初始路径后,对这个初始路径继续优化的步骤才起作用的,它对于这个初始路径的生成没有帮助。
根据高中数学知识可以知道,在椭圆上的点到椭圆两焦点的距离之和相同,椭圆外的点的距离到两焦点的距离之和大于椭圆上的点到两焦点的距离之和,椭圆内的点反之。
回顾一下RRT*的搜索图,根据上面这个知识点可以发现,其实RRT在已经得到一条可行路径之后,可以将采样空间收缩到一个椭圆形区域中,区域之外的点对于缩短规划出的路径长度并没有实际价值。
informed RRT就是的主要思想就是上面这种思想,在获取可行路径之后,将采样空间限制在一个椭圆形区域中,并且随着路径长度的不断缩短,逐渐缩小该椭圆形区域。这个思想其实在以前就有,但是提出informed RRT的论文中提出了对这个椭圆形区域直接采样的方法。
可能有人会直接想,这里只不过是缩小了采样空间,并不会明显改进算法。但是实际上,当拓展到高维空间时,效率的提升是巨大的。
那么,如何表达这个椭圆呢?下面介绍椭圆采样区域的表达方式

先在标准椭圆的方程中采样,再将采样点旋转平移到实际采样区域,需要两个矩阵:平移向量、旋转矩阵。这两个参数只需要在初始化时计算即可
转换后的坐标为:
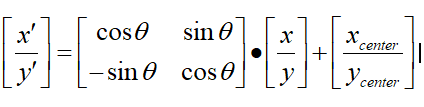

利用超椭圆体然后在二维平面映射

这里放一段.m文件取椭圆随机点的代码(思路如方法2):

除了采样过程外,Informed RRT*的流程和RRT*是一样的。

伪代码中是在RRT的伪代码基础上改的,标红的地方是informed RRT 更改的地方。可以看出,其实主体框架上面并没有太多更改,实际上也是,主要的更改都在第七行,也就是采样这一步。

这是采样这一步的伪代码。informed RRT将目前已经搜索到的最短路径作为cbest,起点和终点之间的距离作为cmin,以此构建椭圆。当还没有规划结果时,cbest为inf,也就是和经典RRT没有区别。
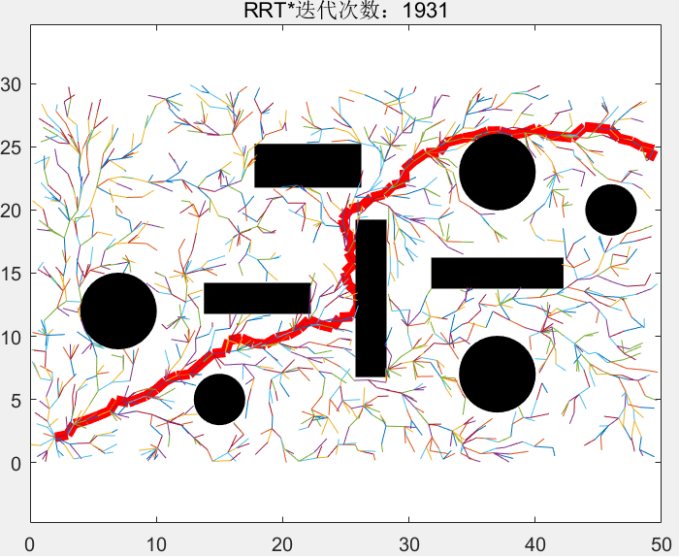
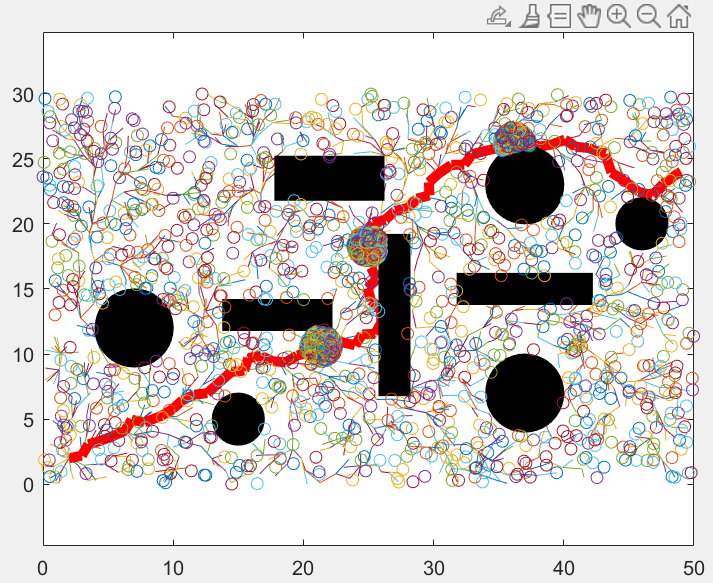
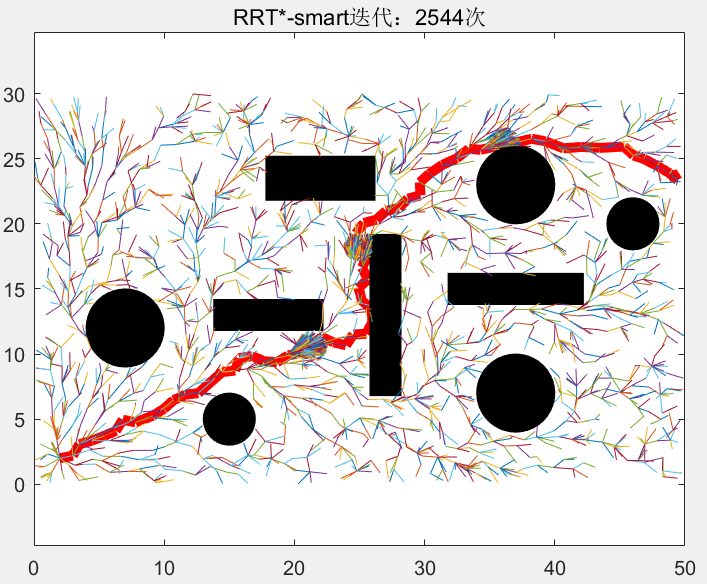
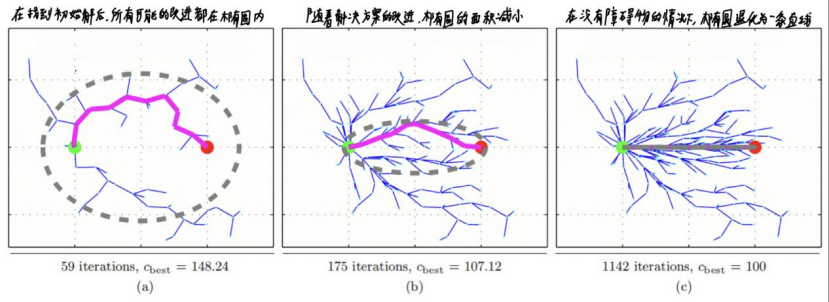
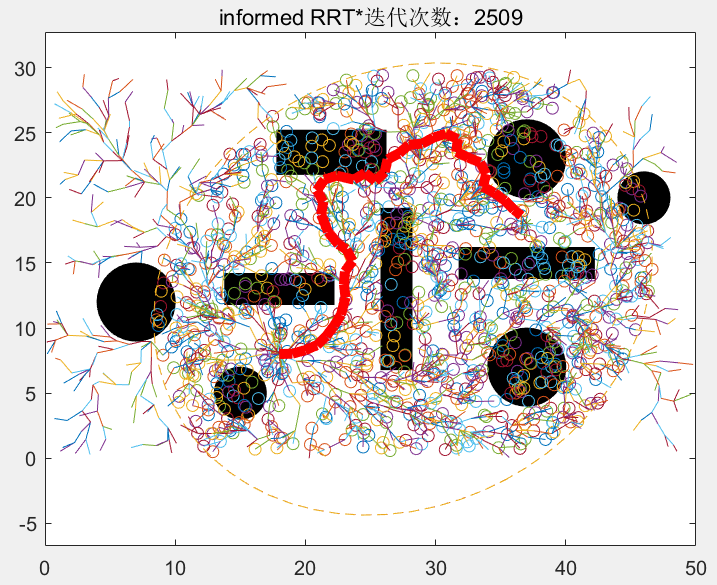
程序在寻找初始路径的过程和普通RRT*一样,在全局域中随机撒点,迭代到1282次时首次找到初始路径,然后我们以起始点和目标点为焦点,初始路径的长度为点到两焦点的距离之和,画出一个椭圆:

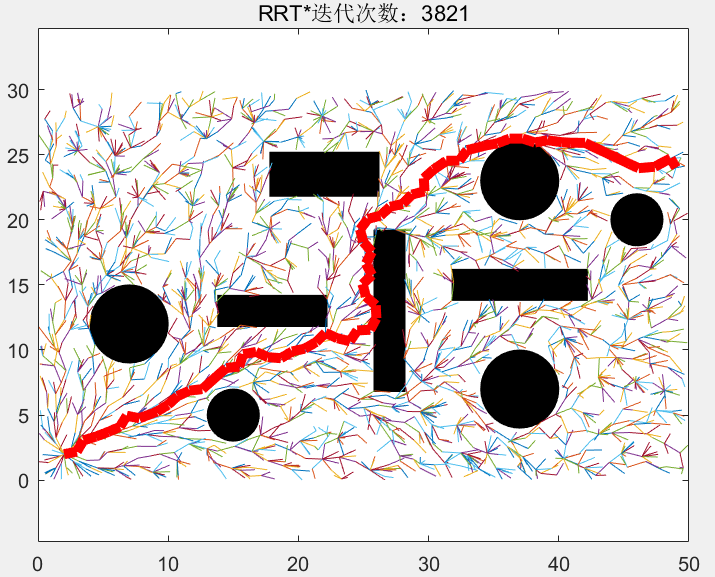
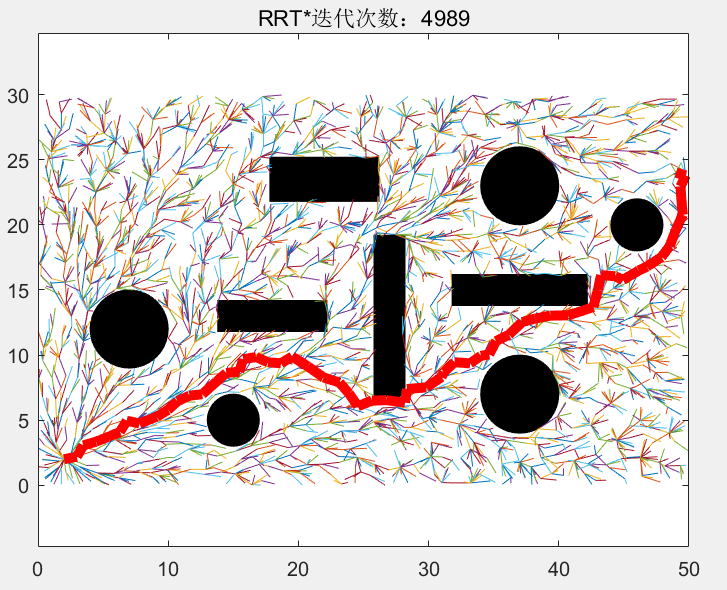
我们随后的随机点的选取范围不再是全局域了,新采的样本点被限制在这个椭圆中,下图中的圆圈代表迭代1283-2509次的随机点的分布,可见,新的随机点全部被限制在椭圆中:
当迭代到2510次时,新的总长度更短的路径被找到,,随后,我们以起始点和目标点为焦点,以这个新的路径的长度为到两焦点的距离,画出一个比之前更小的椭圆:
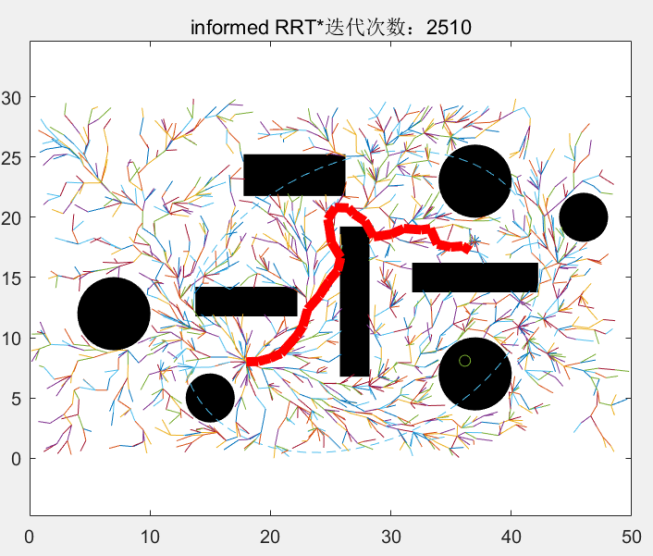
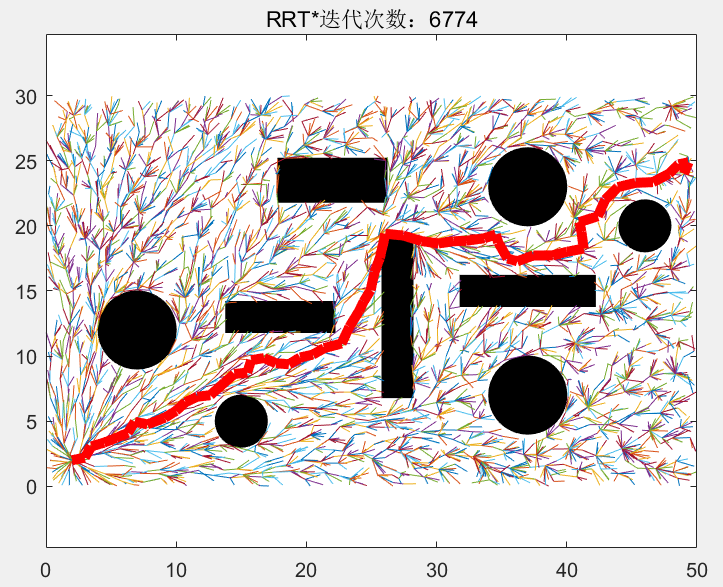
同样的,迭代次数为2510-2865次的循环中的新的随机点被限制在这个新的更小的椭圆中,使随机点资源进一步集中:
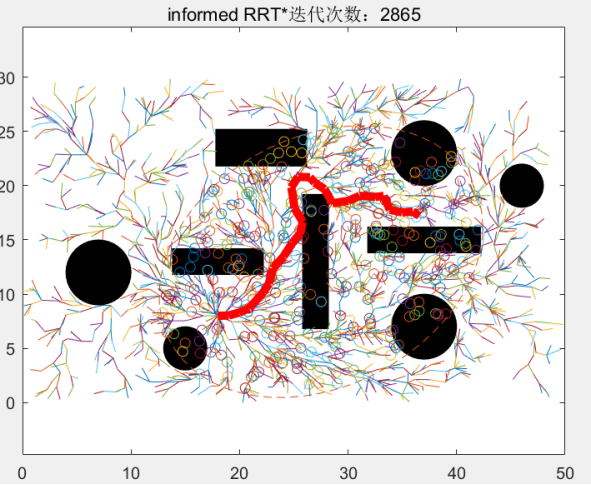
当迭代到2866次时,找到一个路径更短的路径:
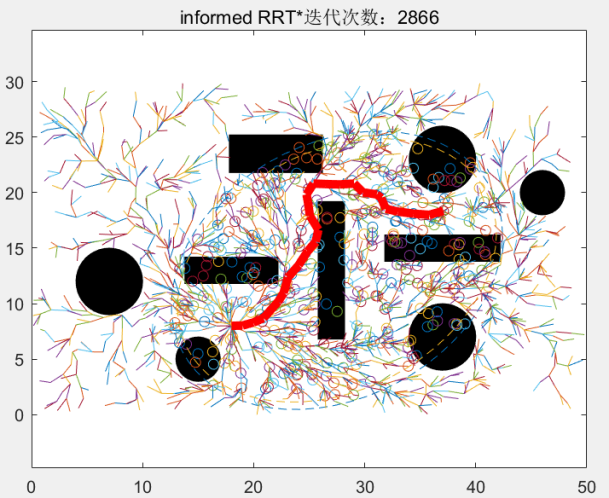
Informed RRT*: Optimal Sampling-based Path Planning Focused via Direct Sampling of an Admissible Ellipsoidal Heuristic
简单来说,BIT*是结合了Informed RRT*和FMT*的优点的一种算法。回顾一下,Informed RRT*是对RRT*的一种优化,在RRT*生成一个初始路径后,则以初始路径的长度,起始点和目标点为焦点,画一个椭圆,Informed RRT*在后续随机采点时,只取落在这个椭圆内的点,一次采一个点,重复lm次。FMT*则与RRT那一套不同,它不是边采点,边生长树,而是一次性提前在整个区域(不包含障碍物区域)内采lm个点,只重复一次。
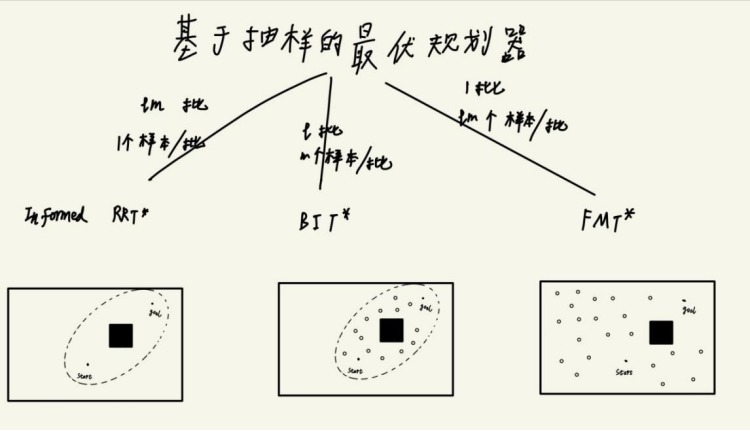
下面我们来说说,Informed RRT*和优缺点FMT*,然后就知道为什么要引出BIT*了。
先说FMT*,FMT*的优点是从起始位置开始构建,没有重布线过程,因此节约时间,适用于复杂的障碍物环境。但是FMT*的缺点是,它只有1批,FMT*路径的精度完全取决于当前批撒点的密度,当你想要提升精度时,只能重新开始一批,重新更密集的撒点,然后重新开始规划。
再说Informed RRT*,Informed RRT*的优点恰好弥补了FMT*的缺点,想要提升精度,只需撒更多的点就好了,而Informed RRT*的撒点过程时一直在进行的,它一批只撒一个点,重复很多批,开始新的批的时候之前的信息不会被抛弃,只要Informed RRT*一直撒点,就可以达到任意精度。但是Informed RRT*的缺点也显而易见,它需要重布线,计算效率低。
所以自然就想到,能不能利用FMT*的优点,提前撒好点,不用重布线,提升计算效率,
又能多批进行,以不断提升精度?当然能,这就是BIT*算法
BIT*的过程总结为下图:
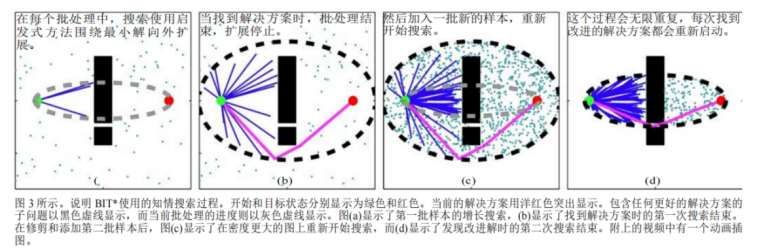



1、Batch Informed Trees (BIT*): Informed Asymptotically Optimal Anytime Search
2、Batch Informed Trees (BIT*): Sampling-based Optimal Planning via the Heuristically Guided Search of Implicit Random Geometric Graphs
几种RRT对比如下:
RRT及其变种都是依托于采样+在树结构上加减枝的形式进行路径规划的,具有全局收敛特性,但是效率稳定性不高。不过可以针对性地对其主要函数进行优化进行效率的改进:优化采样,优化树结构等。一种加速RRT的思路就是,从起始点和目标节点同时生长RRT树,这就是connected_RRT。此外,针对变化的环境,还有extend_RRT和Dynamic_RRT。
RRT*是一种趋近于最优路径的方案,它通过重布线来实现这一目的,它在理论上能达到最优解,但它全局随机撒点的特性导致它在远离目标路径的地方做了过多的生长。
为了集中优化资源,RRT*-smart应运而生,它比较在乎路径和障碍物的拐点的附近的优化,它通过路径优化步骤判断出路径和障碍物的拐点,并在拐点的邻域内投入更多的资源(即撒更多的点),以实现集中优化资源。
但RRT*-smart依然浪费了太多的随机点在远离目标路径的区域,那什么才叫不远离目标路径的区域呢?informed RRT*则解决了这一问题,它利用初始路径的长度,起始点和目标点,画出了一个椭圆,informed RRT*认为,这个椭圆区域就是不远离目标路径的区域,生成这个椭圆后,后续的随机撒点只洒在这个椭圆区域内,当更优的路径被发现,则根据这个新路径的长度,缩小椭圆,进一步在有效区域集中撒点资源,以实现加速。
然而,RRT*类的算法是总会面临一个问题,那就是重布线,这个令RRT*能够逼近最优解的创新恰恰成为了它慢的原因。
于是,另一种思路被提出,那就是提前给定随机点,然后通过启发式函数来连接这些点以生长路径,这就是FMT*,FMT*专门针对解决高维构型空间中的复杂运动规划问题,在预先确定的采样点数量上执行前向动态规划递归,并相应地通过在代价到达空间中稳步向外移动生成路径树。FMT*能很快的找到一条路径,但是当我们想对这条路径进行优化时,只有通过加密随机采样点的方式,然而,FMT*是一种单批算法,面对新的采样点分布时,它只能重新开始计算。
为了融合informed RRT*在有效区域集中随机点的特点和FMT*快速生长的特点,就诞生了BIT*。它能够在椭圆区域内分批撒点,实现快速生长的同时,还能自我优化。
https://www.youtube.com/watch?v=TQIoCC48gp4
基于搜索的路径规划算法基本都是一个套路,它们都是根据启发函数重备用节点的集合中来寻找下一个节点,不同的启发函数也就有不同的搜索类算法。
搜索类算法是离散化的算法,体现在整个图的区域是由有限个小方块区域组成的。我们暂且把这些小方块区域称为“节点”。因此,整个区域被有限个节点填充,且每个节点的邻居节点为有限个。
设置两个集合OPEN,CLOSE,OPEN初始状态设为{x_init},CLOSE 初始状态设为空集。


依据不同的启发式函数,从open集中选择一个点加入到close集中,然后拓展open集,如上图,右下角的某个点被某种启发式函数选中,加入到close集中,并相继拓展open集
下面介绍下搜索类算法的前进过程:

当上述伪码退出循环后,沿着x_goal的父节点往前回溯极为路径
各搜索类算法的区别在于第三行启发函数的类型的不同,导致连接的节点不同。
这里的Best-first-searching和数据结构里学的图搜索算法BFS(广度优先搜索)不是一个东西。完整思想请看我前面写的路径规划(十三)基于搜索的路径规划算法-前言
下面说说Best-first-searching的核心思想:
Best-first Searching的启发式函数f(x)=dist(x,x_goal),即Best-first Searching每一步都在预选集合中寻找距离目标节点最近的的那个节点。
这里的dist(x,y),如果节点x,y无法通过碰撞检测,则为inf,如果能通过碰撞检测,可以直接用欧几里得距离代替。
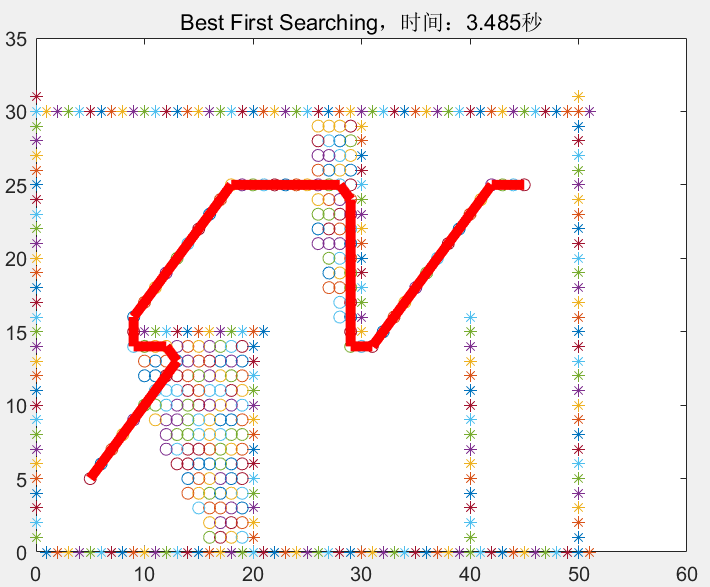
https://blog.csdn.net/potato_uncle/article/details/109124362?ops_request_misc=&request_id=&biz_id=102&utm_term=best%20first%20search&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-109124362.nonecase&spm=1018.2226.3001.4187
完整思想请看我前面写的路径规划(十三)基于搜索的路径规划算法-前言,和其他的基于搜索的路径规划算法的区别仅在于启发式函数的不同
Dijkstra则和Best-first-searching相反,它不是将到目标节点的距离作为启发式函数,而是将到起始节点的距离作为启发式函数。
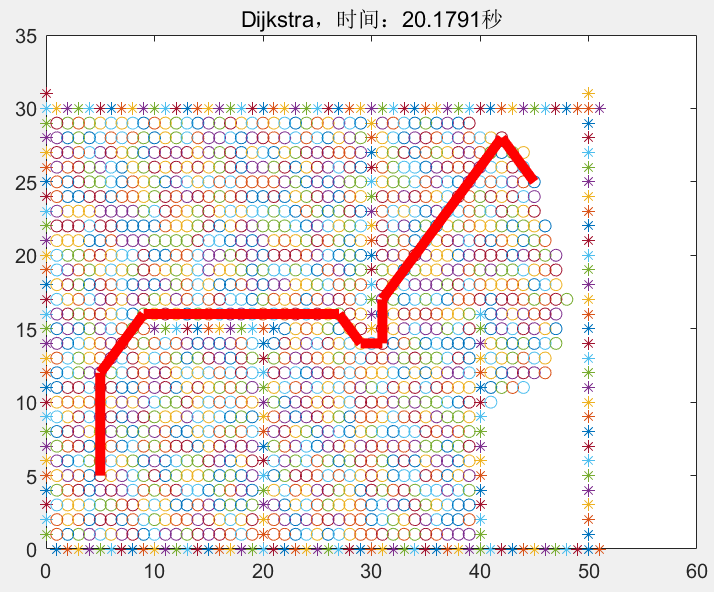
完整思想请看我前面写的路径规划(十三)基于搜索的路径规划算法-前言,,和其他的基于搜索的路径规划算法的区别仅在于启发式函数的不同
A*则是结合了Best-first Searching和Dijkstra,它将当前节点到初始节点和到目标节点的距离之和作为启发式函数。
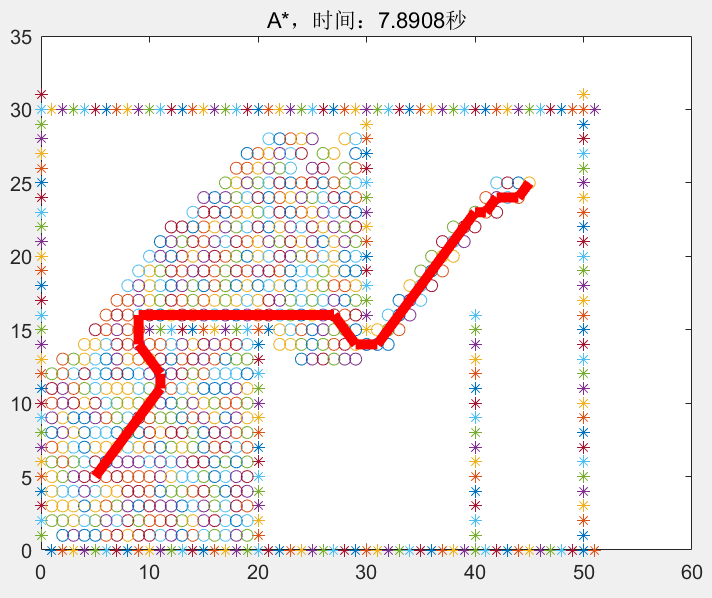
A Formal Basis for the heuristic Determination of Minimum Cost Paths
17.1 原理
完整思想请看我前面写的路径规划(十三)基于搜索的路径规划算法-前言,,和其他的基于搜索的路径规划算法的区别仅在于启发式函数的不同.
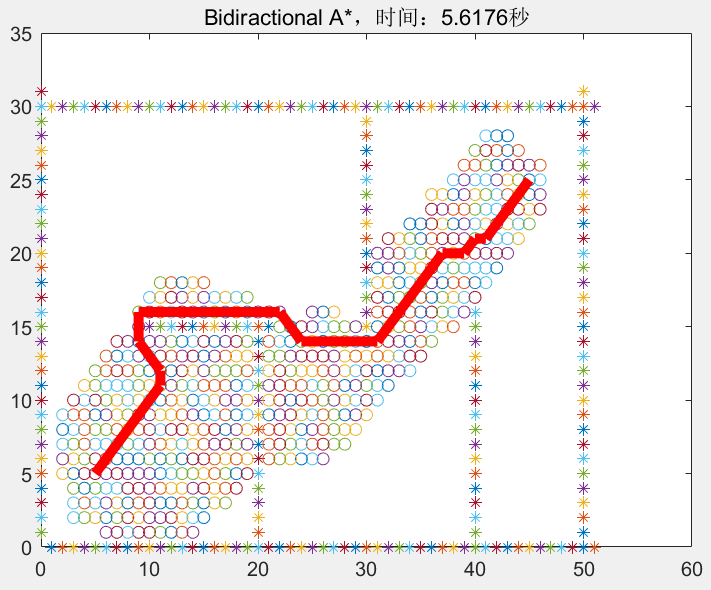
双向A*则稍微复杂些,但可以简单理解为起始节点和终点同时将对方视为目标节点,并按照A*的启发式函数,相向生长,当两者相遇时,则停止迭代,并分别往回追溯自己的父节点即可得到路径。
17.2 程序示例

 公众号
公众号