以下内容为卢朓老师在B站进行的分享,可以作为学习参考:
在介绍广义线性模型之前, 我们先看看常规线性回归模型.
常规线性回归(ConventionalLinear Regression),也称为普通最小二乘法(Ordinary Least Squares, OLS)线性回归,是统计学和机器学习中最基础且广泛应用的一种回归分析技术。
这个可以参考北太天元科普:最小二乘法和线性回归 - 哔哩哔哩 (bilibili.com)
常规线性回归是一种用于分析两个或多个变量之间线性关系的统计方法。它通过拟合一条直线(或超平面)来描述因变量(目标变量)与一个或多个自变量(预测变量)之间的关系。这种模型基于一个基本假设:自变量与因变量之间存在线性关系。
常规线性回归的数学表达式为:
* 简单线性回归(单变量):
* 多元线性回归(多变量):
其中,Y是因变量,X是自变量(在多元线性回归中,X代表多个自变量X_1, X_2, ..., X_n),是截距项,
是回归系数,ε是误差项,表示模型未能解释的变异部分。
常规线性回归通过最小二乘法来拟合模型。最小二乘法的目标是找到最佳的回归系数β0, β1, ..., βn,使得实际观测值与模型预测值之间的残差平方和最小。残差平方和的公式为:
RSS =
其中,是实际观测值,
是模型预测值。
常规线性回归的有效性基于以下假设条件:
* 线性关系:自变量与因变量之间存在线性关系。
* 独立性:观测值之间相互独立。
* 同方差性:误差项的方差恒定。
* 正态性:误差项服从正态分布。
上面的自变量又被称为协变量、预测变量、解释变量, 是那些用于预测或解释 因变量(响应变量)变化的变量。
线性回顾,我们假设因变量 , 我们的目的是寻找
也就是
, 我们假设
.
在广义线性模型(GLM)中,这些自变量通过线性组合的方式影响因变量的分布,即使这种影响在最终模型中可能表现为非线性关系。因此,尽管模型可能包含非线性的元素,但它们仍然被视为“线性”的,因为自变量的影响是通过线性组合传递的, 并通过链接函数与线性预测器建立非线性关系。广义线性模型(GLMs)是统计学中一类非常强大且灵活的回归模型,它扩展了普通线性回归模型的应用范围。本文将对广义线性模型进行详细介绍,并清晰地阐述其数学基础和应用场景。
一、背景与动机
普通线性回归模型假设响应变量服从正态分布,且其均值是预测变量的线性函数。然而,在实际应用中,这一假设往往不成立。例如,在二分类问题中,响应变量通常服从二项分布;在计数数据中,响应变量可能服从泊松分布。为了处理这些非正态分布数据,广义线性模型应运而生。
二、广义线性模型的基本概念
广义线性模型包含三个主要组成部分:
随机部分(random component):定义了响应变量的概率分布。例如,在线性回归中, 遵循正态分布;而在二元逻辑回归中, 遵循二项分布。这是模型中唯一的随机元素,不包含单独的误差项。常见的分布类型包括正态分布、二项分布、泊松分布等。
系统部分(systematic component):描述了模型中的解释变量 及其线性组合。具体来说,就是这些解释变量的加权和,如 。
链接函数(Link function, 记作 η 或 g(μ)):它连接了模型的随机部分(响应变量的分布)和系统部分(解释变量的线性组合)。链接函数 或 是一个函数,它将响应变量的期望值 与解释变量的线性组合 联系起来。通过链接函数,我们可以将线性预测器 (解释变量的线性组合)转换为响应变量的期望值 。这允许我们使用线性模型来描述非线性的关系。在经典回归(即普通最小二乘回归)中,链接函数是恒等函数,即: 这里,链接函数没有改变期望值的形式,因此线性预测器 直接等于响应变量的期望值 。 在逻辑回归中,响应变量 通常是一个二值变量(例如,成功或失败),其期望值 代表成功的概率 。逻辑回归使用logit链接函数,定义为: 其中, 是成功的概率。 通过这个链接函数,我们可以将线性预测器 转换为成功的概率 。具体来说,我们有: 这是逻辑回归中著名的sigmoid函数,它将线性预测器映射到(0, 1)区间内的概率值。
在广义线性模型(GLM)的框架中,假设响应变量 Y 的条件分布属于指数分布族是一个基本的、必需的假设。这个假设是GLM理论构建的基础,它允许我们使用一套系统的方法来处理不同类型的响应变量和预测变量之间的关系。
指数分布族包括了许多常见的分布,如正态分布、二项分布、泊松分布等,这些分布都可以通过GLM进行建模。在这个框架下,我们可以通过指定链接函数来连接线性预测器和响应变量的期望值,从而灵活地适应不同的数据特性和预测需求。
北太天元的用于广义线性模型的拟合.

设响应变量 的条件分布属于指数分布族,其概率密度函数(或概率质量函数)可以表示为:
其中:
- 是自然参数,决定了分布的具体形状。
- 是尺度参数,通常与分布的方差有关。
- 和
是已知函数,用于确保概率密度函数或概率质量函数的积分(或求和)为1。
在广义线性模型中,我们假设:
1. 分布假设:给定预测变量 ,响应变量
的条件分布属于指数分布族。
2. 线性预测器与期望值的联系:响应变量 的数学期望值
是线性预测器
的函数,即
。这里
是链接函数,它决定了线性预测器如何与响应变量的期望值相联系。
3. 自然参数与线性预测器的关系:自然参数 是线性预测器
的函数,即
。这进一步明确了线性预测器如何影响分布的具体形状。
三、常见链接函数与分布类型
- 正态分布(Normal Distribution):
- 用途:通常用于连续数据的预测。
- 链接函数:恒等函数(IdentityFunction),即 。因此,
。
- 二项分布(Binomial Distribution):
- 用途:用于二分类问题(如逻辑回归)。
- 链接函数:Logit 函数(对数几率函数),即 。因此,
(即逻辑函数)。
- 泊松分布(Poisson Distribution):
- 用途:用于计数数据的建模(如事件发生的次数)。
- 链接函数:自然对数函数(Natural LogarithmFunction),即 。因此,
。
- 多项分布(Multinomial Distribution):
- 用途:用于多分类问题。
- 链接函数:Softmax 函数,即对于每个类别 i,有 (在多类别情况下,链接函数应用于每个类别的线性预测器,并确保所有类别的概率之和为1)。
广义线性模型通过指数分布族和链接函数提供了一种灵活的框架,用于建模各种类型的数据和响应变量。通过选择合适的分布类型和链接函数,我们可以构建适应不同数据特性和预测需求的模型。
四、函数拟合和广义线性回归
开普勒第三定律,也称为行星运动定律,描述了行星绕太阳运动的轨道周期与其轨道半长轴之间的关系。具体来说,该定律指出:绕以太阳为焦点的椭圆轨道运行的所有行星,其各自椭圆轨道半长轴的立方与周期的平方之比是一个常量。用数学表达式表示即:a³/T²=k,其中a是轨道半长轴,T是轨道周期,k是一个与行星无关的常量,只与中心天体(在这里是太阳)的质量有关。这个关系实际上是一个非线性关系,因为它涉及到轨道半长轴的立方与周期的平方之比。在非线性关系中,变量之间的关系不是直线或平面,而是曲线或更复杂的形状。开普勒第三定律中的这种非线性关系揭示了行星运动的一个基本规律,即行星的轨道周期与其轨道大小之间存在一个特定的比例关系。
对一系列观测数据进行函数拟合在天文学、物理学、工程学等多个领域中非常常见,用于预测、解释数据背后的物理规律或进行模型优化。函数拟合的目标通常是找到一个数学函数,该函数能够尽可能准确地描述观察的数据点。
在许多情况下,数据可能呈现出非线性关系,这使得直接拟合变得复杂。然而,通过对变量取对数,可以将某些类型的非线性关系转化为线性关系,从而简化拟合过程。这种方法基于对数函数的特性,即对数函数可以将乘法关系转化为加法关系。
具体来说,如果数据呈现出指数关系(例如,),则可以通过对 y 取对数来将其转化为线性关系(我们举得例子还kepler做得 T = 1/k * a^(3/2) 不太一样,但是道理是类似的):
这样,原本的非线性关系就变成了关于$ log(y) 和 x 的线性关系,可以使用线性回归等简单方法来进行拟合。
广义线性模型(GLM)是线性模型的扩展,它允许因变量服从更广泛的概率分布,并通过链接函数将线性预测器与因变量的期望值或分布联系起来。在GLM的框架中,当因变量服从指数分布族(如泊松分布、伽马分布等)时,通常会使用对数链接函数。
将对数转换与GLM联系起来的关键在于,对数转换实际上是一种特殊形式的链接函数。在GLM中,链接函数用于将线性预测器(即自变量的线性组合)映射到因变量的期望值或分布上。对于指数分布族,对数链接函数是一种常用的选择,因为它能够保持因变量与自变量之间的非线性关系(在原始尺度上),同时在线性预测器的尺度上保持线性关系。
因此,当我们通过取对数来转化非线性关系为线性关系并进行拟合时,实际上是在使用一种类似于GLM中的对数链接函数的方法。虽然很多时候我们可以采用更加直观和简单的方法(例如,直接对因变量和自变量单独或者同时取对数,然后使用线性回归),但GLM提供了更严格的统计框架和更广泛的适用性。下面我们用代码给出 数据呈现出指数关系y = a*exp(bx),我们使用两种方法来做数据拟合: 第一种方法是使用对y取对数,然后使用线性回归(或者说最小二乘法);第二种方法是使用GLM(特别是选择泊松分布和对数链接函数)。 第一种方法我们使用北太天元的 polyfit 函数, 第二种方法,我们使用北太天元的 glmfit 函数。
% 生成模拟数据
n = 30; % 数据点数量
x = linspace(0, 10, n)'; % 自变量
a = 2; % 指数函数参数a
b = 0.5; % 指数函数参数b
y = a * exp(b * x) + randn(n, 1) * 0.05; % 因变量,添加了一些噪声
% Kepler的指数函数拟合(假设他已知是指数关系)
% 对y取对数,转化为线性关系
log_y = log(y); % log_y = log(a) + b * x ;
% 使用线性回归拟合转化后的数据
p_kepler = polyfit(x, log_y, 1); % 这里polyfit只用于演示,实际上Kepler可能用其他方法
beta_kepler = [p_kepler(1), exp(p_kepler(2))]; % 注意,我们需要将截距项转化回原始尺度 b = p_kepler(1), a = e^(p_kepler(2))
% 使用glmfit函数进行拟合
% 对于指数关系,我们使用'poisson'分布和对数链接函数(这是GLM中的标准设置)
% 但是,注意MATLAB的glmfit默认不处理指数分布的截距项,因此我们需要手动添加一个常数项
X = [ones(n, 1), x]; % 添加常数项1到自变量中
beta_glm = glmfit(X, y, 'poisson', 'Link', 'log');
% 比较结果
disp('Kepler拟合结果:');
disp(beta_kepler);
disp('GLM拟合结果:');
disp(beta_glm);
% 绘制结果比较
% 原始数据
figure;
scatter(x, y, 'b', 'filled');
hold on;
% Kepler拟合曲线
y_kepler = beta_kepler(2) * exp(beta_kepler(1) * x);
%y_kepler = exp(p_kepler(2)+p_kepler(1) * x);
plot(x, y_kepler, 'r-', 'LineWidth', 2);
% GLM拟合曲线
% 注意,glmfit返回的是对数尺度上的参数,我们需要转化回原始尺度
% 对于泊松分布,GLM的拟合结果是log(mu),所以我们需要使用exp函数
y_glm = exp([ones(size(X,1),1), X] * beta_glm);
plot(x, y_glm, 'g--', 'LineWidth', 2);
legend('原始数据', 'Kepler拟合', 'GLM拟合');
xlabel('x'); ylabel('y');
title('北太天元: Kepler拟合与GLM拟合比较');
hold off;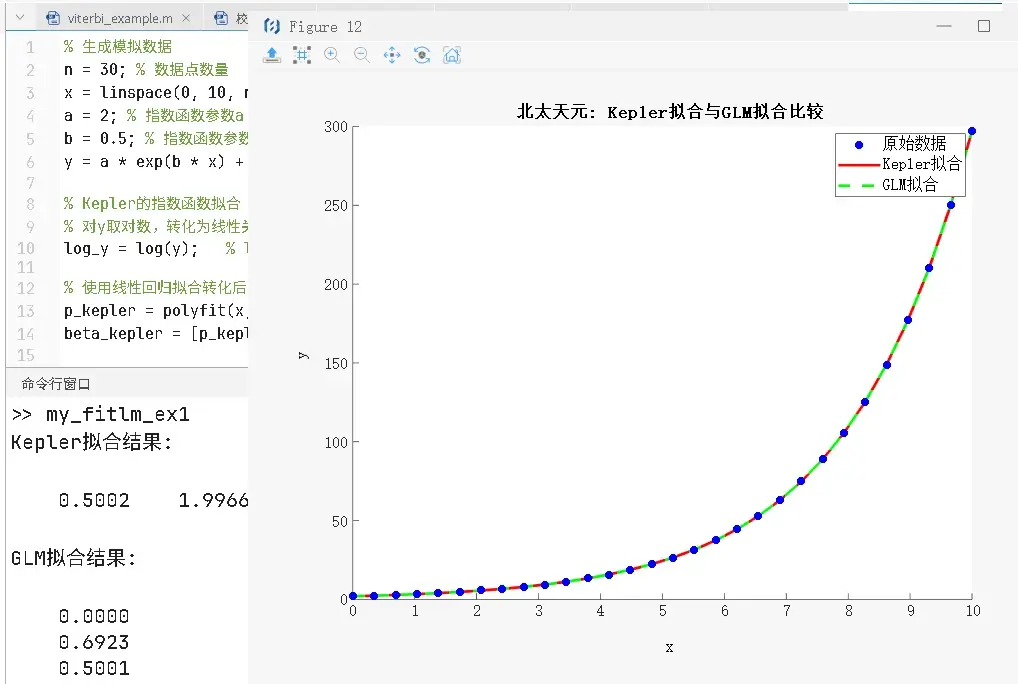
五、应用场景
广义线性模型在各个领域都有广泛的应用,包括但不限于: - 医学:用于疾病诊断、治疗效果评估等。 - 生物学:用于基因表达数据分析、种群动态模型等。 - 经济学:用于需求分析、风险评估等。 - 社会学:用于投票行为分析、犯罪率预测等。
六、glm的链接函数和神经网络的激活函数
广义线性模型(GLM)的链接函数和神经网络的激活函数在作用上有一定的相似性,它们都是为了引入非线性因素,使得模型能够捕捉到数据中的复杂关系。然而,尽管它们在功能上有所重叠,但在发展背景、理论基础以及应用灵活性上确实存在一些差异。
GLM的链接函数起源于统计学的广义线性模型框架,这一框架是在对经典线性回归模型进行扩展的基础上发展起来的。链接函数的主要作用是将线性预测器(即自变量的线性组合)与响应变量的期望值或分布联系起来。由于GLM的理论基础较为坚实,链接函数的选择通常受到严格的数学和统计理论的约束,以确保模型的合理性和可解释性。因此,在GLM中,链接函数的选择往往比较有限,且需要满足一定的数学性质,如单调性和可逆性。
相比之下,神经网络的激活函数则更加灵活多样。神经网络作为一种机器学习算法,其目标是通过对大量数据进行训练,学习到数据中的复杂模式和规律。激活函数在神经网络中扮演着至关重要的角色,它们通过引入非线性因素,使得神经网络能够逼近更加复杂的函数或映射。与GLM的链接函数相比,神经网络的激活函数没有严格的数学和统计理论约束,因此可以选择更加多样化和灵活的函数形式。此外,随着深度学习的发展,人们还不断提出新的激活函数,以适应不同任务和数据的需求。
总的来说,虽然GLM的链接函数和神经网络的激活函数在作用上相似,但它们在发展背景、理论基础以及应用灵活性上存在差异。GLM的链接函数更加注重理论分析和可解释性,而神经网络的激活函数则更加灵活多样,能够适应不同任务和数据的需求。在实际应用中,需要根据具体问题和数据特点选择合适的模型和方法。
七、结论
广义线性模型通过放宽普通线性回归模型的假设,扩展了其应用范围,使其能够处理各种类型的数据和响应变量。通过选择合适的链接函数和分布类型,广义线性模型能够灵活地适应不同的实际问题,为统计分析和数据挖掘提供了强大的工具。
再给出北太天元一个使用glmfit 的例子, 代码如下:
% 生成示例数据
N = 100; % 样本大小
X = randn(N, 2); % 生成两个服从正态分布的预测变量
% 添加常数项(截距项)
X = [ones(N, 1), X];
% 生成二项响应变量(0 或 1)
% 这里我们使用一个逻辑回归模型来生成响应变量,但使用不同的系数
true_beta = [0.5; -0.3; 0.2]; % 真正的回归系数
p = 1 ./ (1 + exp(-X * true_beta)); % 计算响应变量的概率
y = rand(N, 1) < p; % 生成响应变量
% 使用 glmfit 进行逻辑回归
% 指定响应变量分布为 'binomial'
beta_hat = glmfit(X(:,2:3), y, 'binomial'); % 注意:这里我们排除了常数项列
% 输出估计的回归系数
disp('Estimated coefficients:');
disp(beta_hat);
% 计算预测的概率 p_hat = 1 ./ (1 + exp(-X * beta_hat)); % 注意:这里我们添加了常数项1
% 评估模型性能
% 例如,可以计算准确率、精确率、召回率等,但这里我们仅计算准确率作为示例
predicted_y = p_hat > 0.5; % 使用 0.5 作为阈值进行预测
accuracy = mean(predicted_y == y);
disp(['Accuracy: ',
num2str(accuracy)]);
 公众号
公众号